
5. Pandas - Merging DataFrames#
Often, we may want to pool and combine data from different sources.
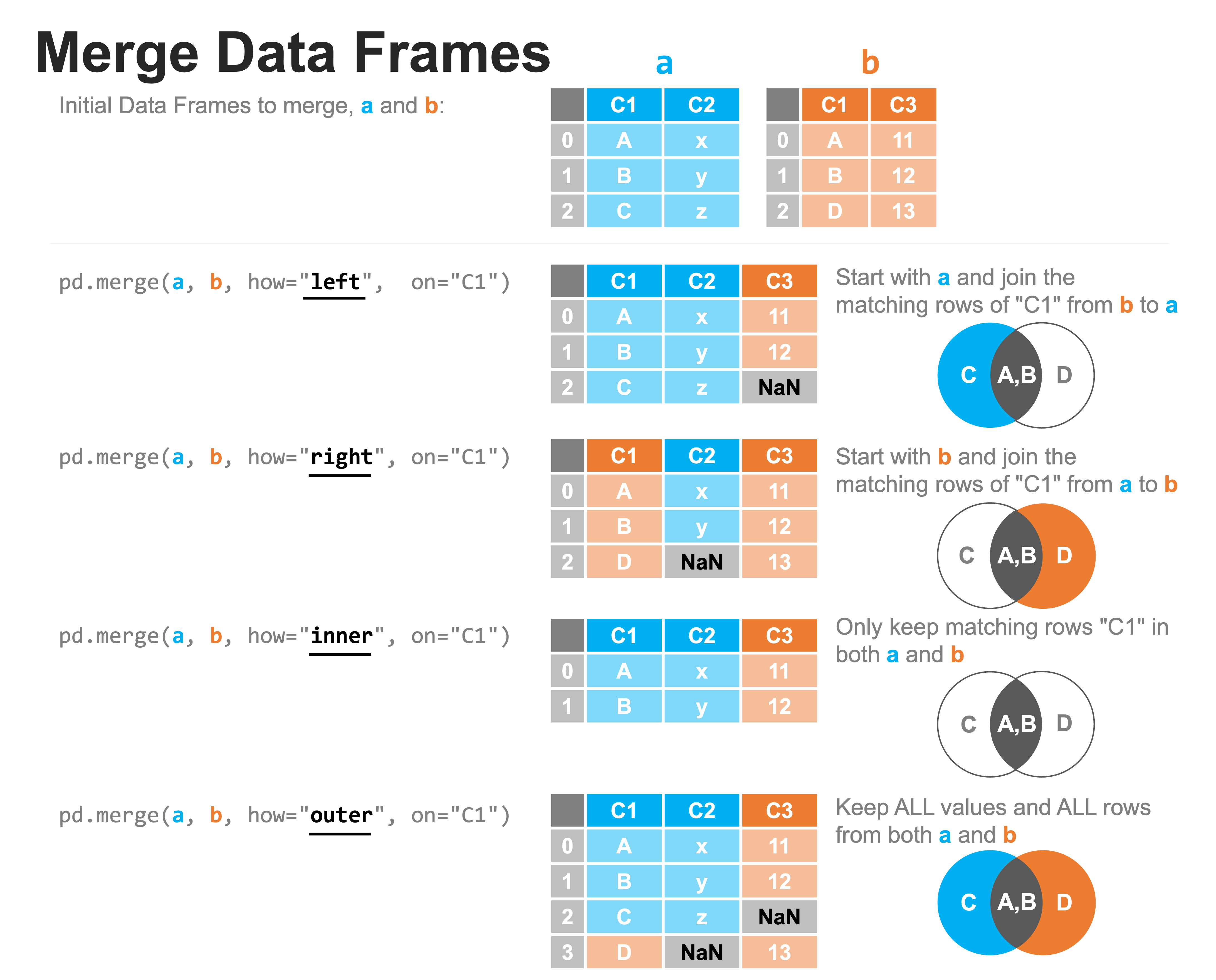
The Pandas function merge() allows you to combine data horizontally (adding columns) from different DataFrames based on common values in specified columns.
If you are familiar with SQL, this is a JOIN.

Let’s go through the arguments of this function:
left and right are used to denote the two dataframes being merged.
on, left_on, right_on are the key columns (can be one or more) by which rows are matched.
If the two dataframes share column names, use on. The on column will only be represented once in the merged dataframe.
If not, they can still be matched using left_on and right_on. The key columns will be preserved as separate in the merged dataframe.
how describes the type of merge, which rows are kept and which rows are discarded depending on keys that do and don’t have corresponding matches.
‘left’ keep all the rows from the left dataframe. For a row with no corresponding data from the right dataframe, there will be missing data in the right half.
‘right’ keep all the rows from the right dataframe. For a row with no corresponding data from the left dataframe, there will be missing data in the left half.
‘inner’ keep only data where there are corresponding keys. There will be no missing row data, but this method throws away the most data.
‘outer’ keep all rows from both dataframes. This method doesn’t discard any data, but you may have missing data in both the left and right halves.
‘cross’ doesn’t look for matches between left and right keys; in fact, it won’t accept keys as an argument. Instead it makes all the possible combinations of rows from the left and right dataframes.
suffixes are used to disambiguate columns that share the same name. After the merge, the suffixes indicate which columns came from the left and right dataframes.
5.1. More about ‘how’#
read more about the types of merges
import pandas as pd
L_dict = {
'k1':[1, 2, 3, 4, 5],
'l2':['a', 'b', 'c', 'd', 'e'],
'twos':[12, 34, 45, 56, 67],
'threes':[123, 234, 345, 456, 567]
}
R_dict = {
'k1':[2, 4, 5, 6],
'r2':['b', 'd', 'c', 'a'],
'threes': [555, 666, 777, 888],
'fours': [5555, 6666, 7777, 8888]
}
L_df = pd.DataFrame(L_dict)
R_df = pd.DataFrame(R_dict)
display(L_df)
display(R_df)
| k1 | l2 | twos | threes | |
|---|---|---|---|---|
| 0 | 1 | a | 12 | 123 |
| 1 | 2 | b | 34 | 234 |
| 2 | 3 | c | 45 | 345 |
| 3 | 4 | d | 56 | 456 |
| 4 | 5 | e | 67 | 567 |
| k1 | r2 | threes | fours | |
|---|---|---|---|---|
| 0 | 2 | b | 555 | 5555 |
| 1 | 4 | d | 666 | 6666 |
| 2 | 5 | c | 777 | 7777 |
| 3 | 6 | a | 888 | 8888 |
# Left and Right
left = pd.merge(L_df, R_df, how = 'left',
left_on = ['k1', 'l2'], right_on = ['k1', 'r2'],
suffixes = ['_L', '_R'])
# left = pd.merge(L_df, R_df, how = 'left',
# left_on = ['k1', 'l2'], right_on = ['k1', 'r2'],
# suffixes = ['_L', '_R'])
# display(left)
right = pd.merge(L_df, R_df, how = 'right', left_on = 'l2', right_on = 'r2', suffixes = ['_L', '_R'])
display(right)
| k1_L | l2 | twos | threes_L | k1_R | r2 | threes_R | fours | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2 | b | 34 | 234 | 2 | b | 555 | 5555 |
| 1 | 4 | d | 56 | 456 | 4 | d | 666 | 6666 |
| 2 | 3 | c | 45 | 345 | 5 | c | 777 | 7777 |
| 3 | 1 | a | 12 | 123 | 6 | a | 888 | 8888 |
# Outer and inner
outer = pd.merge(L_df, R_df, how = 'outer', on = 'k1', suffixes = ['_L', '_R'])
inner = pd.merge(L_df, R_df, how = 'inner', on = 'k1', suffixes = ['_L', '_R'])
display(outer)
display(inner)
| k1 | l2 | twos | threes_L | r2 | threes_R | fours | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | a | 12.0 | 123.0 | NaN | NaN | NaN |
| 1 | 2 | b | 34.0 | 234.0 | b | 555.0 | 5555.0 |
| 2 | 3 | c | 45.0 | 345.0 | NaN | NaN | NaN |
| 3 | 4 | d | 56.0 | 456.0 | d | 666.0 | 6666.0 |
| 4 | 5 | e | 67.0 | 567.0 | c | 777.0 | 7777.0 |
| 5 | 6 | NaN | NaN | NaN | a | 888.0 | 8888.0 |
| k1 | l2 | twos | threes_L | r2 | threes_R | fours | |
|---|---|---|---|---|---|---|---|
| 0 | 2 | b | 34 | 234 | b | 555 | 5555 |
| 1 | 4 | d | 56 | 456 | d | 666 | 6666 |
| 2 | 5 | e | 67 | 567 | c | 777 | 7777 |
cross = pd.merge(L_df, R_df, how = 'cross', suffixes = ['_L', '_R'])
display(cross)
| k1_L | l2 | twos | threes_L | k1_R | r2 | threes_R | fours | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | a | 12 | 123 | 2 | b | 555 | 5555 |
| 1 | 1 | a | 12 | 123 | 4 | d | 666 | 6666 |
| 2 | 1 | a | 12 | 123 | 5 | c | 777 | 7777 |
| 3 | 1 | a | 12 | 123 | 6 | a | 888 | 8888 |
| 4 | 2 | b | 34 | 234 | 2 | b | 555 | 5555 |
| 5 | 2 | b | 34 | 234 | 4 | d | 666 | 6666 |
| 6 | 2 | b | 34 | 234 | 5 | c | 777 | 7777 |
| 7 | 2 | b | 34 | 234 | 6 | a | 888 | 8888 |
| 8 | 3 | c | 45 | 345 | 2 | b | 555 | 5555 |
| 9 | 3 | c | 45 | 345 | 4 | d | 666 | 6666 |
| 10 | 3 | c | 45 | 345 | 5 | c | 777 | 7777 |
| 11 | 3 | c | 45 | 345 | 6 | a | 888 | 8888 |
| 12 | 4 | d | 56 | 456 | 2 | b | 555 | 5555 |
| 13 | 4 | d | 56 | 456 | 4 | d | 666 | 6666 |
| 14 | 4 | d | 56 | 456 | 5 | c | 777 | 7777 |
| 15 | 4 | d | 56 | 456 | 6 | a | 888 | 8888 |
| 16 | 5 | e | 67 | 567 | 2 | b | 555 | 5555 |
| 17 | 5 | e | 67 | 567 | 4 | d | 666 | 6666 |
| 18 | 5 | e | 67 | 567 | 5 | c | 777 | 7777 |
| 19 | 5 | e | 67 | 567 | 6 | a | 888 | 8888 |
5.1.1. Example#
Looking again at the dataframe of election results. It’s not formatted in the most convenient way. Let’s improve the organization of this dataframe.
Goal:
One row for each county-and-year combo.
Within a row, there should be columns for each party candidate and the number of votes they received.
No duplicated or unnecessary data.
elec_df = pd.read_csv('https://raw.githubusercontent.com/GettysburgDataScience/datasets/refs/heads/main/us_political/countypres_2000-2024.csv')
elec_df.head()
| year | state | state_po | county_name | county_fips | office | candidate | party | candidatevotes | totalvotes | version | mode | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | US PRESIDENT | AL GORE | DEMOCRAT | 4942 | 17208 | 20250821 | TOTAL |
| 1 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | US PRESIDENT | GEORGE W. BUSH | REPUBLICAN | 11993 | 17208 | 20250821 | TOTAL |
| 2 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | US PRESIDENT | OTHER | OTHER | 113 | 17208 | 20250821 | TOTAL |
| 3 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | US PRESIDENT | RALPH NADER | GREEN | 160 | 17208 | 20250821 | TOTAL |
| 4 | 2000 | ALABAMA | AL | BALDWIN | 1003.0 | US PRESIDENT | AL GORE | DEMOCRAT | 13997 | 56480 | 20250821 | TOTAL |
elec_df['mode'].unique()
elec_df = elec_df.query('mode in ["TOTAL", "TOTAL VOTES"]')
elec_df = elec_df.drop(columns = ['office', 'version', 'mode'])
elec_df.head()
| year | state | state_po | county_name | county_fips | candidate | party | candidatevotes | totalvotes | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | AL GORE | DEMOCRAT | 4942 | 17208 |
| 1 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | GEORGE W. BUSH | REPUBLICAN | 11993 | 17208 |
| 2 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | OTHER | OTHER | 113 | 17208 |
| 3 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | RALPH NADER | GREEN | 160 | 17208 |
| 4 | 2000 | ALABAMA | AL | BALDWIN | 1003.0 | AL GORE | DEMOCRAT | 13997 | 56480 |
elec_df.rename(columns = {'candidatevotes':'votes'}, inplace = True)
R_df = elec_df.query('party == "REPUBLICAN"')
D_df = elec_df.query('party == "DEMOCRAT"')
display(R_df.head(2))
display(D_df.head(2))
| year | state | state_po | county_name | county_fips | candidate | party | votes | totalvotes | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | GEORGE W. BUSH | REPUBLICAN | 11993 | 17208 |
| 5 | 2000 | ALABAMA | AL | BALDWIN | 1003.0 | GEORGE W. BUSH | REPUBLICAN | 40872 | 56480 |
| year | state | state_po | county_name | county_fips | candidate | party | votes | totalvotes | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | ALABAMA | AL | AUTAUGA | 1001.0 | AL GORE | DEMOCRAT | 4942 | 17208 |
| 4 | 2000 | ALABAMA | AL | BALDWIN | 1003.0 | AL GORE | DEMOCRAT | 13997 | 56480 |
# First run this then copy the list of column headers
# elec_df.columns
columns_to_keep = ['year', 'state_po', 'county_name', 'county_fips', 'candidate',
'votes','party', 'totalvotes']
elec_df = elec_df[columns_to_keep]
elec_df.head()
| year | state_po | county_name | county_fips | candidate | votes | party | totalvotes | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2000 | AL | AUTAUGA | 1001.0 | AL GORE | 4942 | DEMOCRAT | 17208 |
| 1 | 2000 | AL | AUTAUGA | 1001.0 | GEORGE W. BUSH | 11993 | REPUBLICAN | 17208 |
| 2 | 2000 | AL | AUTAUGA | 1001.0 | OTHER | 113 | OTHER | 17208 |
| 3 | 2000 | AL | AUTAUGA | 1001.0 | RALPH NADER | 160 | GREEN | 17208 |
| 4 | 2000 | AL | BALDWIN | 1003.0 | AL GORE | 13997 | DEMOCRAT | 56480 |