
2. Logistic Regression#
Is it regression or classification? Yes.
Let’s start differently, with an example.
2.1. Example: Simple Logistic Regression as a Classifier#
Let’s revisit the breast cancer dataset. The data comprise numerous physical features of a tumor (e.g. area, texture, symmetry, etc.) and each feature set is labeled with a binary target, benign or malignant.
Note: In the original data set, benign tumors are labeled 1 and malignant tumors 0. This seems backwards to me and every time I look at these data, my wrong intuition beats out my terrible memory. So, in the example below, I’ve swapped the labeling so that 1 and 0 correspond to malignant and benign, respectively. So:
0 = benign
1 = malignant
We’ll first fit a simple logistic regression, predicting malignancy based on just one feature.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
# Load the breast cancer dataset
bc_df, y = load_breast_cancer(return_X_y=True, as_frame=True)
# Adding the target to the DataFrame of features
# AND FLIPPING THE LABELS OF THE TARGET
# 1 - malignant
# 0 - benign
bc_df['y'] = 1-y
display(bc_df.describe())
display(bc_df['y'].describe())
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | ... | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | ... | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 | 569.000000 |
| mean | 14.127292 | 19.289649 | 91.969033 | 654.889104 | 0.096360 | 0.104341 | 0.088799 | 0.048919 | 0.181162 | 0.062798 | ... | 25.677223 | 107.261213 | 880.583128 | 0.132369 | 0.254265 | 0.272188 | 0.114606 | 0.290076 | 0.083946 | 0.372583 |
| std | 3.524049 | 4.301036 | 24.298981 | 351.914129 | 0.014064 | 0.052813 | 0.079720 | 0.038803 | 0.027414 | 0.007060 | ... | 6.146258 | 33.602542 | 569.356993 | 0.022832 | 0.157336 | 0.208624 | 0.065732 | 0.061867 | 0.018061 | 0.483918 |
| min | 6.981000 | 9.710000 | 43.790000 | 143.500000 | 0.052630 | 0.019380 | 0.000000 | 0.000000 | 0.106000 | 0.049960 | ... | 12.020000 | 50.410000 | 185.200000 | 0.071170 | 0.027290 | 0.000000 | 0.000000 | 0.156500 | 0.055040 | 0.000000 |
| 25% | 11.700000 | 16.170000 | 75.170000 | 420.300000 | 0.086370 | 0.064920 | 0.029560 | 0.020310 | 0.161900 | 0.057700 | ... | 21.080000 | 84.110000 | 515.300000 | 0.116600 | 0.147200 | 0.114500 | 0.064930 | 0.250400 | 0.071460 | 0.000000 |
| 50% | 13.370000 | 18.840000 | 86.240000 | 551.100000 | 0.095870 | 0.092630 | 0.061540 | 0.033500 | 0.179200 | 0.061540 | ... | 25.410000 | 97.660000 | 686.500000 | 0.131300 | 0.211900 | 0.226700 | 0.099930 | 0.282200 | 0.080040 | 0.000000 |
| 75% | 15.780000 | 21.800000 | 104.100000 | 782.700000 | 0.105300 | 0.130400 | 0.130700 | 0.074000 | 0.195700 | 0.066120 | ... | 29.720000 | 125.400000 | 1084.000000 | 0.146000 | 0.339100 | 0.382900 | 0.161400 | 0.317900 | 0.092080 | 1.000000 |
| max | 28.110000 | 39.280000 | 188.500000 | 2501.000000 | 0.163400 | 0.345400 | 0.426800 | 0.201200 | 0.304000 | 0.097440 | ... | 49.540000 | 251.200000 | 4254.000000 | 0.222600 | 1.058000 | 1.252000 | 0.291000 | 0.663800 | 0.207500 | 1.000000 |
8 rows × 31 columns
count 569.000000
mean 0.372583
std 0.483918
min 0.000000
25% 0.000000
50% 0.000000
75% 1.000000
max 1.000000
Name: y, dtype: float64
# sns.pairplot(bc_df)
# plt.show()
bc_corr = bc_df.corr()
fig, ax = plt.subplots(1,1,figsize = (15,15))
sns.heatmap(bc_corr, annot = True, fmt = '.2f')
plt.show()
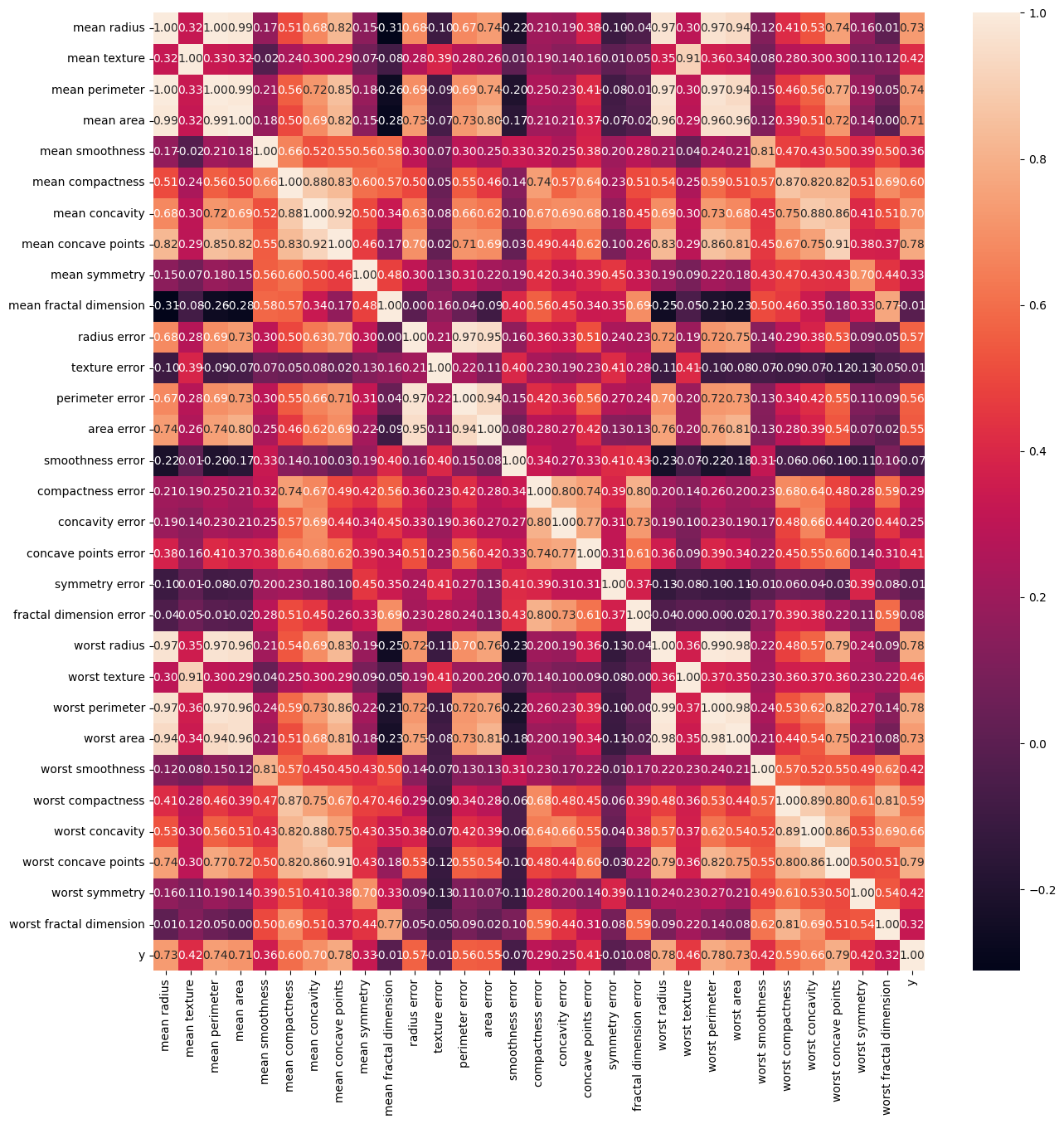
bc_corr = bc_df.corr()
bc_corr[['y']].sort_values(by = 'y', ascending = False)
| y | |
|---|---|
| y | 1.000000 |
| worst concave points | 0.793566 |
| worst perimeter | 0.782914 |
| mean concave points | 0.776614 |
| worst radius | 0.776454 |
| mean perimeter | 0.742636 |
| worst area | 0.733825 |
| mean radius | 0.730029 |
| mean area | 0.708984 |
| mean concavity | 0.696360 |
| worst concavity | 0.659610 |
| mean compactness | 0.596534 |
| worst compactness | 0.590998 |
| radius error | 0.567134 |
| perimeter error | 0.556141 |
| area error | 0.548236 |
| worst texture | 0.456903 |
| worst smoothness | 0.421465 |
| worst symmetry | 0.416294 |
| mean texture | 0.415185 |
| concave points error | 0.408042 |
| mean smoothness | 0.358560 |
| mean symmetry | 0.330499 |
| worst fractal dimension | 0.323872 |
| compactness error | 0.292999 |
| concavity error | 0.253730 |
| fractal dimension error | 0.077972 |
| symmetry error | -0.006522 |
| texture error | -0.008303 |
| mean fractal dimension | -0.012838 |
| smoothness error | -0.067016 |
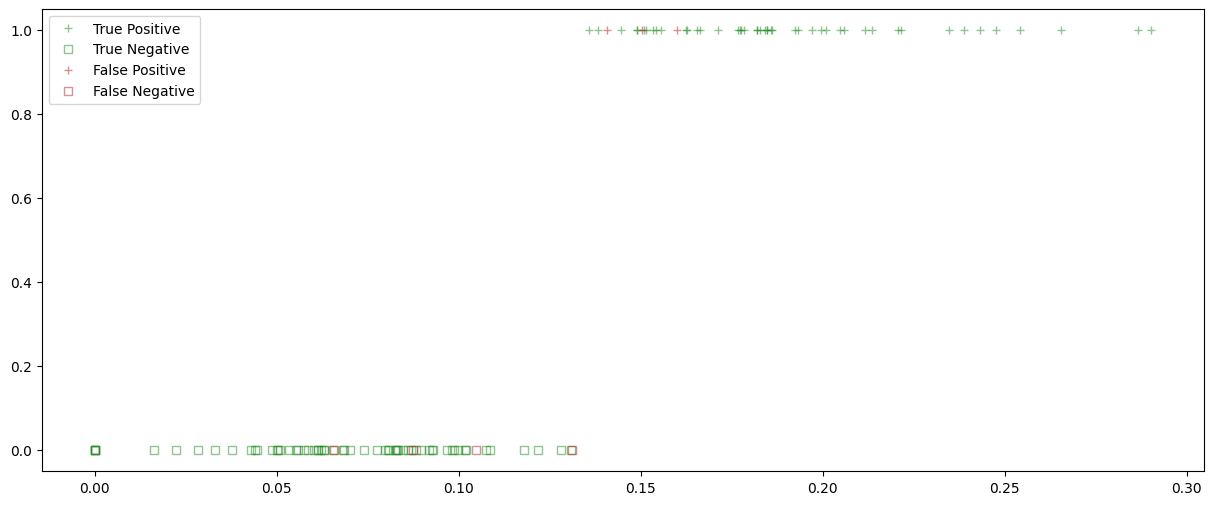
feature = 'worst concave points'
X = bc_df[[feature]]
y = bc_df['y']
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import ConfusionMatrixDisplay
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=59)
# Train a logistic regression model
model_LogReg = LogisticRegression(penalty = None, max_iter = 10000)
model_LogReg.fit(X_train, y_train)
# Make predictions
y_pred = model_LogReg.predict(X_test)
TP = (y_pred==1) & (y_test==1)
TN = (y_pred==0) & (y_test==0)
FP = (y_pred==1) & (y_test==0)
FN = (y_pred==0) & (y_test==1)
right = 'forestgreen'
wrong = 'firebrick'
positive = '+'
negative = 's'
fig, ax = plt.subplots(1,1, figsize = (15, 6))
ax.plot(X_test[TP], y_pred[TP], color = right, alpha = 0.5, marker = positive, linewidth = 0, label = 'True Positive')
ax.plot(X_test[TN], y_pred[TN], color = right, markerfacecolor='none',alpha = 0.5, marker = negative, linewidth = 0, label = 'True Negative')
ax.plot(X_test[FP], y_pred[FP], color = wrong, alpha = 0.5, marker = positive, linewidth = 0, label = 'False Positive')
ax.plot(X_test[FN], y_pred[FN], color = wrong, markerfacecolor='none', alpha = 0.5, marker = negative, linewidth = 0, label = 'False Negative')
plt.legend()
plt.show()
y_pred_prob = model_LogReg.predict_proba(X_test)
y_pred_prob
array([[5.44077032e-01, 4.55922968e-01],
[9.62062910e-01, 3.79370899e-02],
[9.57331930e-01, 4.26680697e-02],
[9.99721296e-01, 2.78704480e-04],
[1.46279385e-01, 8.53720615e-01],
[2.08250039e-01, 7.91749961e-01],
[9.99721296e-01, 2.78704480e-04],
[8.87634417e-01, 1.12365583e-01],
[9.05480794e-01, 9.45192059e-02],
[8.75698342e-01, 1.24301658e-01],
[1.25467803e-01, 8.74532197e-01],
[1.18044894e-02, 9.88195511e-01],
[2.51504627e-01, 7.48495373e-01],
[6.74321801e-01, 3.25678199e-01],
[5.83207275e-01, 4.16792725e-01],
[9.13925978e-02, 9.08607402e-01],
[9.84872909e-01, 1.51270914e-02],
[9.90642327e-01, 9.35767331e-03],
[9.62771546e-01, 3.72284541e-02],
[5.37995787e-01, 4.62004213e-01],
[9.93737280e-01, 6.26271980e-03],
[9.56828937e-01, 4.31710631e-02],
[4.19100013e-02, 9.58089999e-01],
[2.81397609e-01, 7.18602391e-01],
[1.19545310e-01, 8.80454690e-01],
[6.51251169e-02, 9.34874883e-01],
[9.95730447e-01, 4.26955263e-03],
[2.82637326e-01, 7.17362674e-01],
[9.98423814e-01, 1.57618596e-03],
[1.67298032e-01, 8.32701968e-01],
[9.92748756e-01, 7.25124437e-03],
[8.21984874e-01, 1.78015126e-01],
[8.45805817e-03, 9.91541942e-01],
[2.57311209e-01, 7.42688791e-01],
[1.44000467e-01, 8.55999533e-01],
[9.45816607e-01, 5.41833934e-02],
[4.93604510e-02, 9.50639549e-01],
[9.94545476e-01, 5.45452389e-03],
[9.84624642e-01, 1.53753577e-02],
[7.49056048e-03, 9.92509440e-01],
[2.68934852e-02, 9.73106515e-01],
[7.21985647e-01, 2.78014353e-01],
[9.99721296e-01, 2.78704480e-04],
[4.21565347e-02, 9.57843465e-01],
[8.53803448e-05, 9.99914620e-01],
[4.57519380e-03, 9.95424806e-01],
[4.80376467e-03, 9.95196235e-01],
[9.48482438e-01, 5.15175616e-02],
[9.90081448e-01, 9.91855209e-03],
[2.03050833e-02, 9.79694917e-01],
[2.22736444e-01, 7.77263556e-01],
[9.28301925e-01, 7.16980749e-02],
[9.68693845e-01, 3.13061549e-02],
[1.73688304e-02, 9.82631170e-01],
[9.40399971e-04, 9.99059600e-01],
[9.93891585e-01, 6.10841495e-03],
[9.96122594e-01, 3.87740572e-03],
[9.74880458e-01, 2.51195423e-02],
[9.98907860e-01, 1.09213978e-03],
[3.90571874e-02, 9.60942813e-01],
[1.26930061e-02, 9.87306994e-01],
[9.57952801e-01, 4.20471993e-02],
[3.37541527e-01, 6.62458473e-01],
[2.63204709e-01, 7.36795291e-01],
[2.54884107e-02, 9.74511589e-01],
[6.04436804e-02, 9.39556320e-01],
[9.88205705e-01, 1.17942949e-02],
[4.93604510e-02, 9.50639549e-01],
[3.14502725e-04, 9.99685497e-01],
[9.97886484e-01, 2.11351555e-03],
[3.97524251e-02, 9.60247575e-01],
[9.64592586e-01, 3.54074144e-02],
[9.87007610e-01, 1.29923902e-02],
[9.99721296e-01, 2.78704480e-04],
[1.22328155e-03, 9.98776718e-01],
[9.97204301e-01, 2.79569920e-03],
[4.73877860e-02, 9.52612214e-01],
[8.55048130e-01, 1.44951870e-01],
[2.29160968e-01, 7.70839032e-01],
[9.41556212e-01, 5.84437883e-02],
[6.84922452e-05, 9.99931508e-01],
[9.88205705e-01, 1.17942949e-02],
[8.32482479e-01, 1.67517521e-01],
[6.32859195e-02, 9.36714080e-01],
[9.52374732e-01, 4.76252677e-02],
[6.70139405e-02, 9.32986060e-01],
[9.99721296e-01, 2.78704480e-04],
[8.95446175e-01, 1.04553825e-01],
[9.23081659e-01, 7.69183412e-02],
[9.91747022e-01, 8.25297820e-03],
[9.82019225e-01, 1.79807747e-02],
[1.60613162e-02, 9.83938684e-01],
[4.36650887e-02, 9.56334911e-01],
[9.55986599e-01, 4.40134013e-02],
[9.36329283e-01, 6.36707175e-02],
[9.25015210e-01, 7.49847904e-02],
[9.44579811e-01, 5.54201895e-02],
[2.06934066e-03, 9.97930659e-01],
[9.94034854e-01, 5.96514559e-03],
[9.87007610e-01, 1.29923902e-02],
[9.81910797e-01, 1.80892033e-02],
[4.29859288e-01, 5.70140712e-01],
[8.98053722e-01, 1.01946278e-01],
[8.73685169e-01, 1.26314831e-01],
[1.60087715e-03, 9.98399123e-01],
[9.89012068e-01, 1.09879322e-02],
[9.87575970e-01, 1.24240303e-02],
[9.99241979e-01, 7.58021348e-04],
[9.95845992e-01, 4.15400758e-03],
[9.79845732e-01, 2.01542680e-02],
[6.20354615e-04, 9.99379645e-01],
[3.94277545e-01, 6.05722455e-01],
[4.66180777e-01, 5.33819223e-01],
[9.91605518e-01, 8.39448225e-03]])
fig, ax = plt.subplots(1,1, figsize = (15, 6))
ax.plot(X_test[TP], y_pred_prob[TP,1], color = right, alpha = 0.5, marker = positive, linewidth = 0, label = 'True Positive')
ax.plot(X_test[TN], y_pred_prob[TN,1], color = right, markerfacecolor='none',alpha = 0.5, marker = negative, linewidth = 0, label = 'True Negative')
ax.plot(X_test[FP], y_pred_prob[FP,1], color = wrong, alpha = 0.5, marker = positive, linewidth = 0, label = 'False Positive')
ax.plot(X_test[FN], y_pred_prob[FN,1], color = wrong, markerfacecolor='none', alpha = 0.5, marker = negative, linewidth = 0, label = 'False Negative')
ax.set_xlabel(feature)
ax.set_ylabel('Predicted Malignancy (Prob %)')
plt.legend()
plt.axhline(y = 0.5, color = 'k', linestyle = '--', alpha = 0.2)
plt.show()
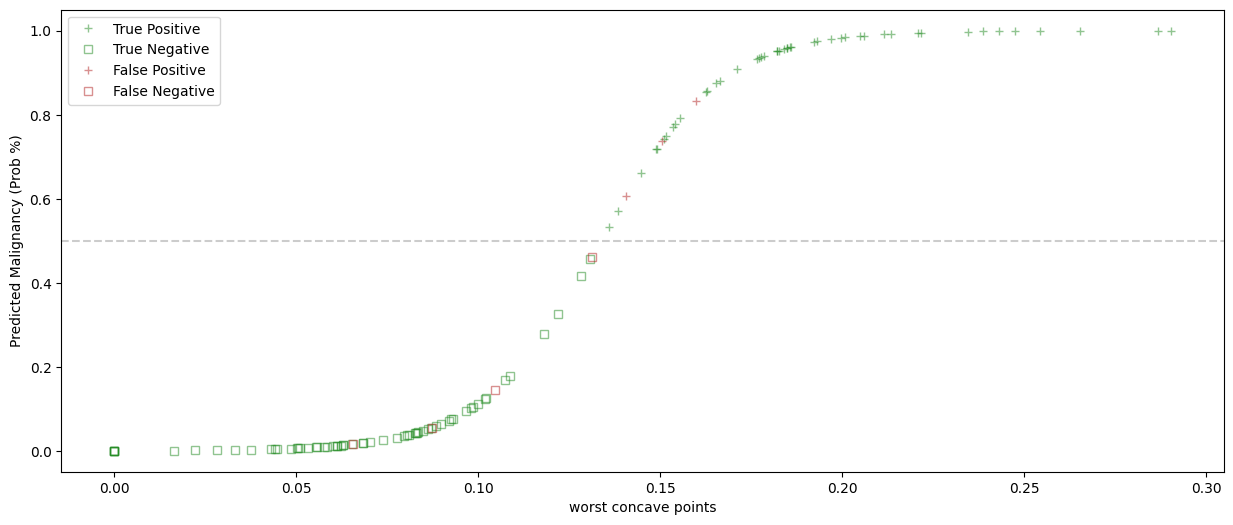
What is this shape?
2.2. The Logistic Function#
The logistic function is a smooth monotonically increasing (means goes up as x goes up) curve with a range of (0, 1). It trends to 0 as x decreases and trends to 1 as x increases with a value of 0.5 at x=0.
This is the logistic function:
Let’s take a look at this function.
t = np.arange(-5, 5, 0.1)
logistic = lambda t: 1/(1 + np.exp(-t))
fig, ax = plt.subplots(2,1, figsize=(10, 10))
ax[0].plot(t, np.exp(t))
ax[0].set_title('Exponential function exp(t)')
ax[1].plot(t, logistic(t))
ax[1].set_title('Logistic function')
ax[1].set_xlabel('t')
ax[1].set_ylabel('Prob')
plt.show()
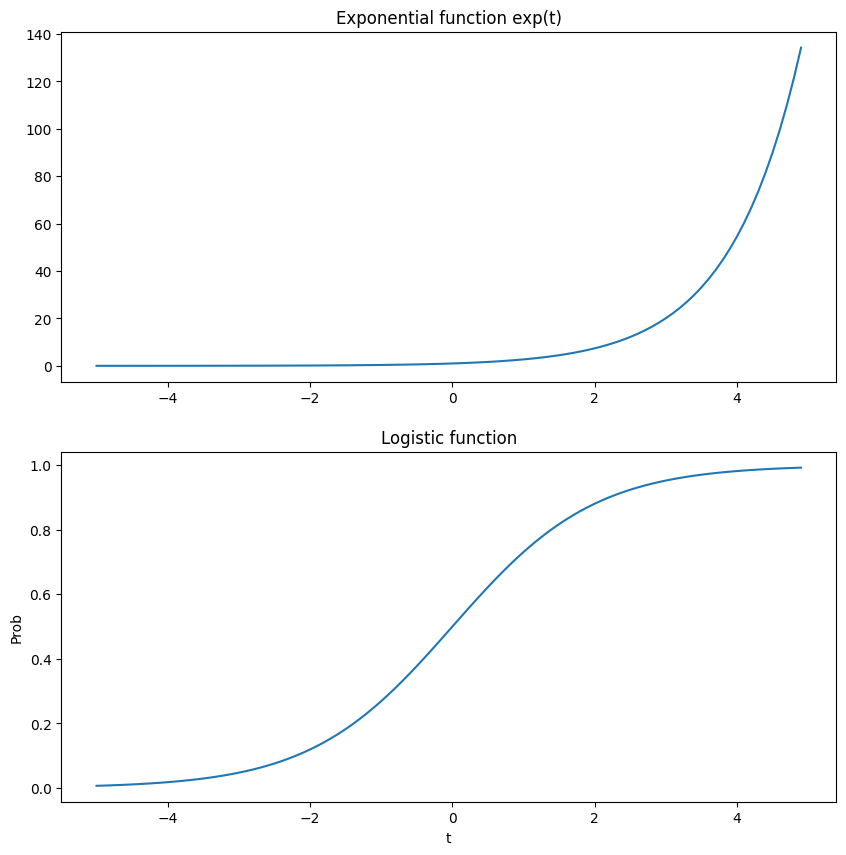
For the plots above:
as t gets to be a big positive number, \(\exp(-t)\) goes to 0 and \(\sigma(t)\) goes to 1.
as t gets to be a big negative number, \(\exp(-t)\) goes to \(+\infty\) and \(\sigma(t)\) goes to 0.
The logistic function actually furnishes a probability. When we use logistic regression for classification, we set a decision threshold for the probability, 50% by default.
We denote the predicted probability as \(\hat{p}\).
If \(\hat{p}=\sigma(t)>0.5\) then 1 is more likely than 0, so classify as 1
If \(\hat{p}=\sigma(t)<0.5\) then 0 is more likely than 1, so classify as 0
50% is a default threshold. It’s a good decision value if either case has equal consequence.
Improving Precision: We can raise the threshold if we want to be more discerning about what we classify as 1.
Improving Recall: Conversely, we can lower the threshold if we want to catch more instances of 1.
2.3. Logistic and Linear Regression#
Why are these two topics in the same chapter?
Let’s look back at the logistic function?
What are the parameters of this model? I don’t see any. That’s because they’re hidden inside \(t\).
The value of \(t\) is the output of a linear model (and it can be any flavor of regularized linear model too!). So the parameters of a logistic regression are actually the coefficients of a linear regression (or Lasso or Ridge or ElasticNet). What does this linear model do?
The linear equation maps feature vectors to the range \((-\infty, +\infty)\). Features that should be classified as 1 get assigned positive numbers, larger for more certain classifications; features that should be classified as 0 get assigned negative numbers, larger negative for more certain classifications.
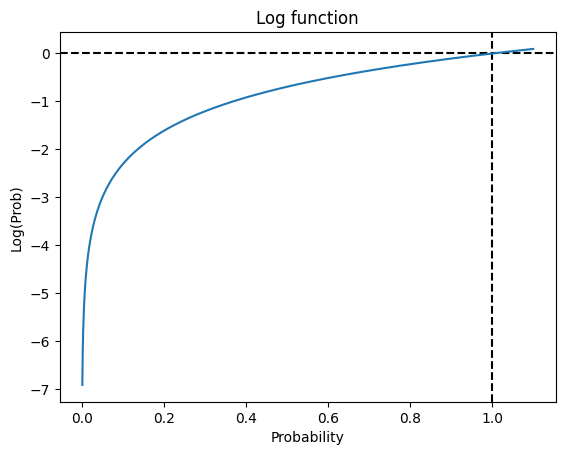
2.3.1. Cost Function#
The loss function minimized for any prediction is:
The cost function minimized for logistic regression is the log-loss function.
np.log(0.5)
np.float64(-0.6931471805599453)
t = np.arange(0.001,1.1, 0.001)
y = np.log(t)
plt.title('Log function')
plt.axvline(x=1, color = 'k', linestyle = '--')
plt.axhline(y=0, color = 'k', linestyle = '--')
plt.xlabel(f'Probability')
plt.ylabel(f'Log(Prob)')
plt.plot(t, y)
plt.show()
2.4. Back to the Example#
Now, let’s use all of our features.
%%capture
from sklearn.preprocessing import StandardScaler
X = bc_df.drop('y', axis = 1)
y = bc_df['y']
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Scale the data, since we are using multiple features
ss = StandardScaler()
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.fit_transform(X_test)
# Train a logistic regression model
model_LogReg = LogisticRegression(penalty = None, max_iter = 10000)
model_LogReg.fit(X_train_scaled, y_train)
# Make predictions
y_pred_train = model_LogReg.predict(X_train_scaled)
y_pred = model_LogReg.predict(X_test_scaled)
y_pred_prob = model_LogReg.predict_proba(X_test_scaled)
TP = (y_pred==1) & (y_test==1)
TN = (y_pred==0) & (y_test==0)
FP = (y_pred==1) & (y_test==0)
FN = (y_pred==0) & (y_test==1)
fig, ax = plt.subplots(1,1, figsize = (15, 6))
ax.plot(X_test[TP], y_pred[TP], color = right, alpha = 0.5, marker = positive, linewidth = 0, label = 'True Positive')
ax.plot(X_test[TN], y_pred[TN], color = right, markerfacecolor='none',alpha = 0.5, marker = negative, linewidth = 0, label = 'True Negative')
ax.plot(X_test[FP], y_pred[FP], color = wrong, alpha = 0.5, marker = positive, linewidth = 0, label = 'False Positive')
ax.plot(X_test[FN], y_pred[FN], color = wrong, markerfacecolor='none', alpha = 0.5, marker = negative, linewidth = 0, label = 'False Negative')
plt.show()
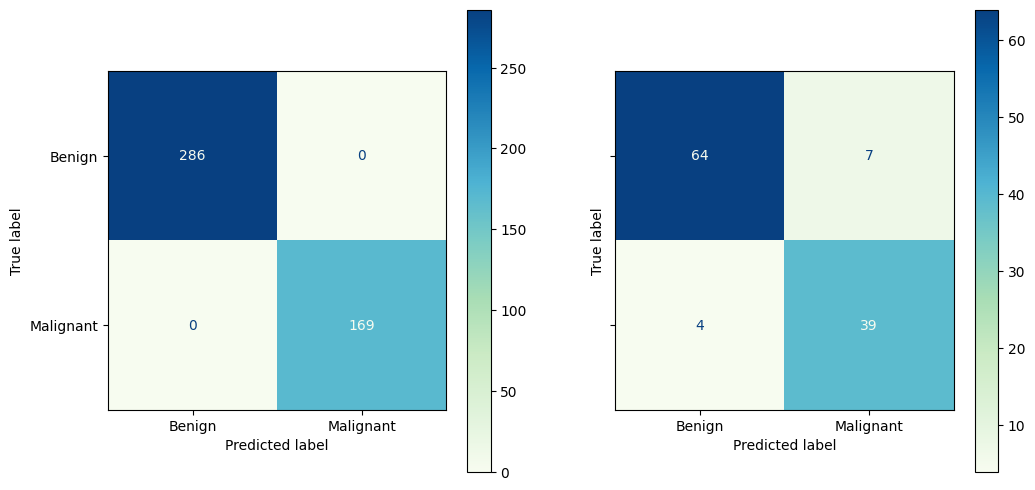
2.4.1. Assessing the model#
How’d we do?
fig, ax = plt.subplots(1,2, figsize = (12,6), sharey=True)
ConfusionMatrixDisplay.from_predictions(y_train, y_pred_train,
# normalize = 'true',
display_labels = ['Benign', 'Malignant'],
cmap = 'GnBu',
ax = ax[0])
ConfusionMatrixDisplay.from_predictions(y_test, y_pred,
# normalize = 'true',
display_labels = ['Benign', 'Malignant'],
cmap = 'GnBu',
ax = ax[1])
plt.show()
2.5. Regularization in Logistic Regression#
Take a look at the documentation for LogisticRegression.
The four hyper-parameters you will likely use:
penalty
‘l1’ - use Lasso
‘l2’ - use Ridge (Default)
‘elasticnet’ - use ElasticNet
None - use unregularized linear regression
C - is the regularization parameter BUT C = 1/alpha. Small C is high regularization; large C is low regularization. Annoying.
l1_ratio - if using ‘elasticnet’ penalty, this hyper-parameter balances the amount of L1 (Lasso) and L2 (Ridge) penalties.
closer to 0, more Ridge
closer to 1, more Lasso
max_iter - sometimes, fitting the model won’t converge. Try increasing the value of max_iters (default is 100) and see if that fixes the problem.
solver - different regularizations may require different solvers (how the optimal parameters are found). Let’s look at the documentation.
2.5.1. Improving our model#
The model we fit seems to be over-fitting the data. How do I know this from the confusion matrix?
Let’s use some regularization to see if we can improve the fit.
from sklearn.linear_model import LogisticRegressionCV
%%capture
# Train a logistic regression model
model_LogReg_Ridge = LogisticRegressionCV(penalty = 'l2', Cs = np.logspace(-2,2, 9), cv = 5, max_iter = 10000)
model_LogReg_Ridge.fit(X_train_scaled, y_train)
# Make predictions
y_pred_train = model_LogReg_Ridge.predict(X_train_scaled)
y_pred = model_LogReg_Ridge.predict(X_test_scaled)
y_pred_prob = model_LogReg_Ridge.predict_proba(X_test_scaled)
fig, ax = plt.subplots(1,2, figsize = (12,6), sharey=True)
ConfusionMatrixDisplay.from_predictions(y_train, y_pred_train,
# normalize = 'true',
display_labels = ['Benign', 'Malignant'],
cmap = 'GnBu',
ax = ax[0])
ConfusionMatrixDisplay.from_predictions(y_test, y_pred,
# normalize = 'true',
display_labels = ['Benign', 'Malignant'],
cmap = 'GnBu',
ax = ax[1])
plt.show()
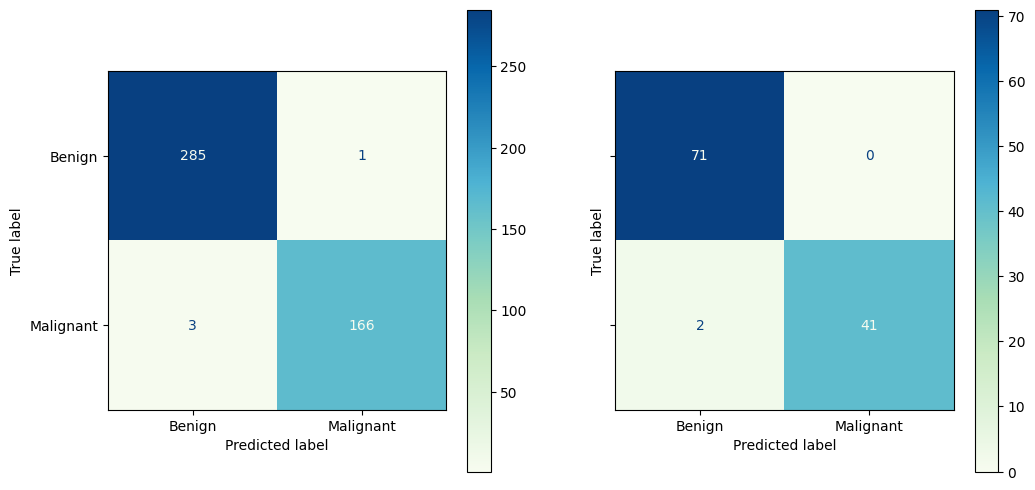
2.5.2. Assessing the model#
What were our most significant features?
model_LogReg_Ridge.__dict__
{'Cs': array([1.00000000e-02, 3.16227766e-02, 1.00000000e-01, 3.16227766e-01,
1.00000000e+00, 3.16227766e+00, 1.00000000e+01, 3.16227766e+01,
1.00000000e+02]),
'fit_intercept': True,
'cv': 5,
'dual': False,
'penalty': 'l2',
'scoring': None,
'tol': 0.0001,
'max_iter': 10000,
'class_weight': None,
'n_jobs': None,
'verbose': 0,
'solver': 'lbfgs',
'refit': True,
'intercept_scaling': 1.0,
'multi_class': 'deprecated',
'random_state': None,
'l1_ratios': None,
'n_features_in_': 30,
'classes_': array([0, 1]),
'Cs_': array([1.00000000e-02, 3.16227766e-02, 1.00000000e-01, 3.16227766e-01,
1.00000000e+00, 3.16227766e+00, 1.00000000e+01, 3.16227766e+01,
1.00000000e+02]),
'n_iter_': array([[[10, 7, 8, 12, 12, 16, 21, 23, 29],
[ 9, 7, 8, 9, 10, 14, 14, 20, 17],
[10, 7, 8, 10, 11, 16, 22, 26, 26],
[10, 6, 7, 9, 11, 13, 21, 30, 26],
[ 9, 8, 8, 12, 11, 15, 20, 15, 11]]], dtype=int32),
'scores_': {np.int64(1): array([[0.93406593, 0.97802198, 0.98901099, 0.98901099, 0.97802198,
0.98901099, 0.98901099, 0.96703297, 0.93406593],
[0.94505495, 0.96703297, 0.96703297, 0.96703297, 0.96703297,
0.97802198, 0.96703297, 0.95604396, 0.95604396],
[0.97802198, 0.98901099, 0.98901099, 1. , 1. ,
1. , 1. , 1. , 1. ],
[0.93406593, 0.95604396, 0.96703297, 0.97802198, 0.97802198,
0.97802198, 0.97802198, 0.97802198, 0.97802198],
[0.93406593, 0.94505495, 0.94505495, 0.93406593, 0.94505495,
0.94505495, 0.94505495, 0.94505495, 0.94505495]])},
'coefs_paths_': {np.int64(1): array([[[ 0.18877931, 0.15354924, 0.18835075, ..., 0.15799421,
0.05308207, -0.62707392],
[ 0.26001545, 0.25317046, 0.25722958, ..., 0.26765068,
0.06680208, -0.62149993],
[ 0.32315174, 0.36240604, 0.31657734, ..., 0.45050076,
0.07887859, -0.58505505],
...,
[-0.19992366, -0.18313838, -0.24642842, ..., 2.79406576,
-0.05705654, 0.22982167],
[-0.72115368, -0.18133544, -0.8247711 , ..., 4.61597812,
-0.33770871, 0.73177235],
[-1.2706124 , 0.50946076, -1.60816546, ..., 7.68106403,
-1.38482576, 0.88623145]],
[[ 0.19407935, 0.1610312 , 0.19282929, ..., 0.15803426,
0.06208549, -0.71466605],
[ 0.2782481 , 0.26927561, 0.27376116, ..., 0.27343663,
0.07898245, -0.74263137],
[ 0.37187738, 0.38911002, 0.36187733, ..., 0.45587393,
0.09207409, -0.76980897],
...,
[ 0.48720426, -0.0536111 , 0.31852832, ..., 2.67600778,
-0.53317192, -0.68615334],
[ 0.39188048, 0.03247218, 0.0542682 , ..., 4.11402491,
-1.36680146, -0.3901461 ],
[ 0.22874718, 0.44243786, -0.29121275, ..., 6.33994447,
-2.42184226, 0.22317786]],
[[ 0.18850543, 0.17367384, 0.1880179 , ..., 0.15486926,
0.07403958, -0.59769658],
[ 0.2711116 , 0.29088627, 0.26713907, ..., 0.25437626,
0.10366637, -0.59128212],
[ 0.35563314, 0.41306985, 0.34485634, ..., 0.41666843,
0.14372282, -0.58508927],
...,
[ 0.16359844, 0.09733587, -0.07076539, ..., 2.52569141,
-0.01463229, 0.23649025],
[-0.282397 , 0.29898835, -0.80273291, ..., 3.84916427,
-0.44224729, 0.94181455],
[-1.02417001, 0.93962826, -2.05384734, ..., 5.80343152,
-1.18953641, 1.68586369]],
[[ 0.19997914, 0.15811623, 0.19773728, ..., 0.16137979,
0.06280437, -0.65213172],
[ 0.28459406, 0.26940186, 0.27864513, ..., 0.26870448,
0.08220969, -0.66336185],
[ 0.36637957, 0.4077656 , 0.35470213, ..., 0.42896016,
0.097046 , -0.66788239],
...,
[-0.24784738, 0.55084161, -0.40231166, ..., 1.80653513,
0.01311299, 0.18548086],
[-0.99713236, 0.62963699, -1.34442754, ..., 2.47198482,
-0.09830574, 0.79818549],
[-2.2579524 , 1.15047913, -2.98278899, ..., 3.56491696,
-0.40545289, 1.60598979]],
[[ 0.19100602, 0.1763199 , 0.18967846, ..., 0.15504789,
0.05368948, -0.67868101],
[ 0.2711364 , 0.29533977, 0.26551771, ..., 0.25671223,
0.07234754, -0.68779421],
[ 0.35676133, 0.41859913, 0.34305118, ..., 0.42267667,
0.1034524 , -0.67676617],
...,
[ 0.42997228, -0.08864118, 0.41415401, ..., 2.60677422,
1.39493816, 0.55349446],
[ 0.48506192, -0.37839758, 0.51076076, ..., 3.80606774,
2.300287 , 1.22929661],
[ 0.7696429 , -0.52645044, 0.82005258, ..., 5.46332712,
3.50667034, 1.95913911]]], shape=(5, 9, 31))},
'C_': array([3.16227766]),
'l1_ratio_': array([None], dtype=object),
'coef_': array([[ 0.30024566, 0.17240886, 0.2191313 , 0.38105667, -0.02093164,
-1.20860703, 1.10774301, 1.89822535, -0.50315616, 0.27157447,
2.04744451, -0.37269222, 0.57003749, 1.4691531 , 0.52954499,
-0.68159526, -0.57761771, 0.52984054, -0.77511646, -0.90946073,
1.20043014, 1.96459618, 0.51709265, 1.21674533, 0.43159841,
-0.1202286 , 1.45955511, 0.91213833, 1.78008332, 0.12361707]]),
'intercept_': array([-0.1816065]),
'l1_ratios_': array([None], dtype=object)}
coefs = model_LogReg_Ridge.coef_[0]
features = X.columns
feature_weights_df = pd.DataFrame({'features':features, 'weights':coefs, 'abs weights': np.abs(coefs)})
feature_weights_df.sort_values(by = 'abs weights', ascending=False)
| features | weights | abs weights | |
|---|---|---|---|
| 10 | radius error | 2.047445 | 2.047445 |
| 21 | worst texture | 1.964596 | 1.964596 |
| 7 | mean concave points | 1.898225 | 1.898225 |
| 28 | worst symmetry | 1.780083 | 1.780083 |
| 13 | area error | 1.469153 | 1.469153 |
| 26 | worst concavity | 1.459555 | 1.459555 |
| 23 | worst area | 1.216745 | 1.216745 |
| 5 | mean compactness | -1.208607 | 1.208607 |
| 20 | worst radius | 1.200430 | 1.200430 |
| 6 | mean concavity | 1.107743 | 1.107743 |
| 27 | worst concave points | 0.912138 | 0.912138 |
| 19 | fractal dimension error | -0.909461 | 0.909461 |
| 18 | symmetry error | -0.775116 | 0.775116 |
| 15 | compactness error | -0.681595 | 0.681595 |
| 16 | concavity error | -0.577618 | 0.577618 |
| 12 | perimeter error | 0.570037 | 0.570037 |
| 17 | concave points error | 0.529841 | 0.529841 |
| 14 | smoothness error | 0.529545 | 0.529545 |
| 22 | worst perimeter | 0.517093 | 0.517093 |
| 8 | mean symmetry | -0.503156 | 0.503156 |
| 24 | worst smoothness | 0.431598 | 0.431598 |
| 3 | mean area | 0.381057 | 0.381057 |
| 11 | texture error | -0.372692 | 0.372692 |
| 0 | mean radius | 0.300246 | 0.300246 |
| 9 | mean fractal dimension | 0.271574 | 0.271574 |
| 2 | mean perimeter | 0.219131 | 0.219131 |
| 1 | mean texture | 0.172409 | 0.172409 |
| 29 | worst fractal dimension | 0.123617 | 0.123617 |
| 25 | worst compactness | -0.120229 | 0.120229 |
| 4 | mean smoothness | -0.020932 | 0.020932 |
2.6. Another Example: Classifying Wines#
In this classification problem, we are given chemical properties of wine as well as a target value corresponding to the vineyard the wine came from. Can we identify which vineyard a wine came from by analyzing the chemical content of the wine itself?
There are three categories of wine in this classification (0,1,2). Below, I’ve set up the problem so that you can fit a binary logistic regression or a multi-class just by toggling the comments on a few lines of code in the next cell. Everything else can stay the same; the LogisticRegression model will handle both cases.
For multi-class classification, we can leave the target variable as it is in the original data set.
For binary classification, we will relabel the target so that:
1 = the wine is from vineyard 1
0 = the wine is from either vineyard 0 or 2 (not 1).
from sklearn.datasets import load_wine
wine_df, y = load_wine(return_X_y=True, as_frame=True)
# Multi-class (3) problem
wine_df['y'] = y
vineyard_labels = ['Vineyard 0', 'Vineyard 1', 'Vineyard 2']
# # Binary Classification problem
# vineyard_labels = ['Not Vineyard 1', 'Vineyard 1']
# wine_df['y'] = 1 * (y==1)
print(wine_df['y'].unique())
wine_df.sample(10)
[0 1 2]
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | y | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 146 | 13.88 | 5.04 | 2.23 | 20.0 | 80.0 | 0.98 | 0.34 | 0.40 | 0.68 | 4.900000 | 0.58 | 1.33 | 415.0 | 2 |
| 171 | 12.77 | 2.39 | 2.28 | 19.5 | 86.0 | 1.39 | 0.51 | 0.48 | 0.64 | 9.899999 | 0.57 | 1.63 | 470.0 | 2 |
| 33 | 13.76 | 1.53 | 2.70 | 19.5 | 132.0 | 2.95 | 2.74 | 0.50 | 1.35 | 5.400000 | 1.25 | 3.00 | 1235.0 | 0 |
| 160 | 12.36 | 3.83 | 2.38 | 21.0 | 88.0 | 2.30 | 0.92 | 0.50 | 1.04 | 7.650000 | 0.56 | 1.58 | 520.0 | 2 |
| 7 | 14.06 | 2.15 | 2.61 | 17.6 | 121.0 | 2.60 | 2.51 | 0.31 | 1.25 | 5.050000 | 1.06 | 3.58 | 1295.0 | 0 |
| 44 | 13.05 | 1.77 | 2.10 | 17.0 | 107.0 | 3.00 | 3.00 | 0.28 | 2.03 | 5.040000 | 0.88 | 3.35 | 885.0 | 0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.800000 | 0.86 | 3.45 | 1480.0 | 0 |
| 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.200000 | 0.61 | 1.60 | 560.0 | 2 |
| 94 | 11.62 | 1.99 | 2.28 | 18.0 | 98.0 | 3.02 | 2.26 | 0.17 | 1.35 | 3.250000 | 1.16 | 2.96 | 345.0 | 1 |
| 110 | 11.46 | 3.74 | 1.82 | 19.5 | 107.0 | 3.18 | 2.58 | 0.24 | 3.58 | 2.900000 | 0.75 | 2.81 | 562.0 | 1 |
# Split the data into features and target
y = wine_df['y']
X = wine_df.drop(columns = ['y'])
X
| alcohol | malic_acid | ash | alcalinity_of_ash | magnesium | total_phenols | flavanoids | nonflavanoid_phenols | proanthocyanins | color_intensity | hue | od280/od315_of_diluted_wines | proline | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 14.23 | 1.71 | 2.43 | 15.6 | 127.0 | 2.80 | 3.06 | 0.28 | 2.29 | 5.64 | 1.04 | 3.92 | 1065.0 |
| 1 | 13.20 | 1.78 | 2.14 | 11.2 | 100.0 | 2.65 | 2.76 | 0.26 | 1.28 | 4.38 | 1.05 | 3.40 | 1050.0 |
| 2 | 13.16 | 2.36 | 2.67 | 18.6 | 101.0 | 2.80 | 3.24 | 0.30 | 2.81 | 5.68 | 1.03 | 3.17 | 1185.0 |
| 3 | 14.37 | 1.95 | 2.50 | 16.8 | 113.0 | 3.85 | 3.49 | 0.24 | 2.18 | 7.80 | 0.86 | 3.45 | 1480.0 |
| 4 | 13.24 | 2.59 | 2.87 | 21.0 | 118.0 | 2.80 | 2.69 | 0.39 | 1.82 | 4.32 | 1.04 | 2.93 | 735.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 173 | 13.71 | 5.65 | 2.45 | 20.5 | 95.0 | 1.68 | 0.61 | 0.52 | 1.06 | 7.70 | 0.64 | 1.74 | 740.0 |
| 174 | 13.40 | 3.91 | 2.48 | 23.0 | 102.0 | 1.80 | 0.75 | 0.43 | 1.41 | 7.30 | 0.70 | 1.56 | 750.0 |
| 175 | 13.27 | 4.28 | 2.26 | 20.0 | 120.0 | 1.59 | 0.69 | 0.43 | 1.35 | 10.20 | 0.59 | 1.56 | 835.0 |
| 176 | 13.17 | 2.59 | 2.37 | 20.0 | 120.0 | 1.65 | 0.68 | 0.53 | 1.46 | 9.30 | 0.60 | 1.62 | 840.0 |
| 177 | 14.13 | 4.10 | 2.74 | 24.5 | 96.0 | 2.05 | 0.76 | 0.56 | 1.35 | 9.20 | 0.61 | 1.60 | 560.0 |
178 rows × 13 columns
# train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y)
# Scale the data
ss = StandardScaler()
X_train_scaled = ss.fit_transform(X_train)
X_test_scaled = ss.transform(X_test)
# I'm choosing to use logistic regression with Lasso (L1) penalty
# One hyper-parameter is solver and not all solvers work for all parameters
logreg_lasso = LogisticRegressionCV(penalty = 'l1', Cs = np.logspace(-3,3,13), solver = 'liblinear', cv = 5)
logreg_lasso.fit(X_train_scaled,y_train)
# Make predictions
y_pred = logreg_lasso.predict(X_test_scaled)
y_pred_train = logreg_lasso.predict(X_train_scaled)
y_proba = logreg_lasso.predict_proba(X_test_scaled)
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/linear_model/_logistic.py:508: FutureWarning: Using the 'liblinear' solver for multiclass classification is deprecated. An error will be raised in 1.8. Either use another solver which supports the multinomial loss or wrap the estimator in a OneVsRestClassifier to keep applying a one-versus-rest scheme.
warnings.warn(
fig, ax = plt.subplots(1,2, figsize = (12,6), sharey=True)
ConfusionMatrixDisplay.from_predictions(y_train, y_pred_train,
# normalize = 'true',
display_labels = vineyard_labels,
cmap = 'GnBu',
ax = ax[0])
ConfusionMatrixDisplay.from_predictions(y_test, y_pred,
# normalize = 'true',
display_labels = vineyard_labels,
cmap = 'GnBu',
ax = ax[1])
plt.show()
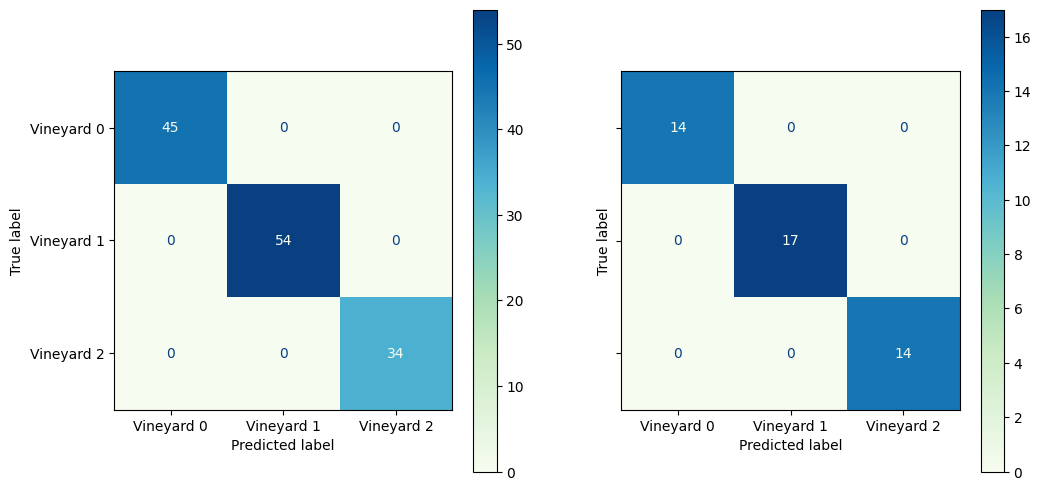
What were the most important features?
Get the feature names from the columns of X
Get the coefficients from the model and calculate their absolute values
Create a dataframe with columns: features, weights, abs weights
Sort by abs weight
# Follow the instructions above
features = X.columns
# When we perform multiple logistic regressions, we get multiple sets of coefficients
# The algorithm fits several binary logistic regressions to solve the multi-class problem
coefs = logreg_lasso.coef_[2]
features_df = pd.DataFrame({'features': features, 'coef':coefs, 'abs coef':np.abs(coefs)})
features_df.sort_values(by = 'abs coef', ascending = False)
| features | coef | abs coef | |
|---|---|---|---|
| 6 | flavanoids | -1.331080 | 1.331080 |
| 9 | color_intensity | 1.077819 | 1.077819 |
| 10 | hue | -0.632350 | 0.632350 |
| 11 | od280/od315_of_diluted_wines | -0.531483 | 0.531483 |
| 1 | malic_acid | 0.367953 | 0.367953 |
| 0 | alcohol | 0.000000 | 0.000000 |
| 2 | ash | 0.000000 | 0.000000 |
| 3 | alcalinity_of_ash | 0.000000 | 0.000000 |
| 4 | magnesium | 0.000000 | 0.000000 |
| 5 | total_phenols | 0.000000 | 0.000000 |
| 7 | nonflavanoid_phenols | 0.000000 | 0.000000 |
| 8 | proanthocyanins | 0.000000 | 0.000000 |
| 12 | proline | 0.000000 | 0.000000 |
y_proba
array([[4.93925698e-02, 2.16819408e-12, 9.50607430e-01],
[7.21646145e-02, 8.89337827e-01, 3.84975583e-02],
[9.59359791e-01, 2.28594725e-11, 4.06402095e-02],
[5.71738310e-02, 8.53588711e-04, 9.41972580e-01],
[5.91991602e-02, 9.23711393e-01, 1.70894463e-02],
[9.74446328e-01, 1.65530898e-19, 2.55536723e-02],
[9.75240874e-01, 9.09994046e-05, 2.46681265e-02],
[9.70603098e-01, 9.02620956e-09, 2.93968928e-02],
[4.65638432e-02, 9.26023936e-01, 2.74122209e-02],
[3.66750499e-02, 4.43472333e-06, 9.63320515e-01],
[9.67029879e-02, 8.70264478e-01, 3.30325345e-02],
[9.84411657e-01, 4.14507905e-12, 1.55883431e-02],
[9.89608080e-01, 1.51867454e-05, 1.03767332e-02],
[1.03584333e-01, 3.21844162e-17, 8.96415667e-01],
[9.24517064e-01, 4.43101536e-03, 7.10519207e-02],
[6.72114348e-02, 1.23639173e-14, 9.32788565e-01],
[9.79332744e-01, 2.04714781e-06, 2.06652088e-02],
[2.63391756e-01, 7.26573531e-01, 1.00347126e-02],
[1.68690232e-02, 8.31006110e-01, 1.52124866e-01],
[9.75619489e-01, 1.11572244e-09, 2.43805102e-02],
[5.40283398e-02, 8.93648484e-01, 5.23231763e-02],
[1.40564106e-01, 1.77355109e-15, 8.59435894e-01],
[1.54357944e-02, 6.36833315e-01, 3.47730891e-01],
[9.85628408e-01, 8.77135602e-14, 1.43715916e-02],
[2.34478694e-02, 9.36366642e-10, 9.76552130e-01],
[9.75506408e-01, 1.40790809e-13, 2.44935924e-02],
[1.70356351e-02, 4.13728427e-05, 9.82922992e-01],
[6.73013149e-02, 9.28324395e-01, 4.37428986e-03],
[9.68137343e-01, 7.79247923e-11, 3.18626572e-02],
[2.41493480e-02, 9.01019055e-01, 7.48315971e-02],
[9.61674931e-01, 1.82610777e-12, 3.83250694e-02],
[1.45081531e-02, 9.79721515e-01, 5.77033208e-03],
[1.94816787e-02, 9.02889590e-01, 7.76287313e-02],
[4.26694924e-02, 1.88314599e-14, 9.57330508e-01],
[1.32149889e-02, 3.34893868e-13, 9.86785011e-01],
[2.44462294e-02, 8.50532818e-06, 9.75545265e-01],
[9.12863885e-01, 3.61547460e-06, 8.71324992e-02],
[7.33202658e-03, 9.21735569e-01, 7.09324040e-02],
[2.41273711e-02, 5.22503903e-02, 9.23622239e-01],
[1.33921739e-02, 6.53611217e-01, 3.32996609e-01],
[5.08668949e-03, 9.39899833e-01, 5.50134779e-02],
[5.74161955e-02, 8.51345166e-01, 9.12386389e-02],
[5.08138015e-02, 3.48139725e-01, 6.01046474e-01],
[3.77273519e-02, 9.06736754e-01, 5.55358939e-02],
[2.37298027e-02, 1.58899078e-11, 9.76270197e-01]])