
4. Tree Methods (continued)#
but first…
4.1. Hyper-parameter Search and Validation#
Tree methods have many hyper-parameters compared to the algorithms we’ve encountered thus far. Here are some from the documentation:
max_depth - how many layers may the tree have
min_samples_split - how many samples must be in a node to allow a split
min_samples_leaf - how many samples must be in a leaf
max_features - the number of features to consider in a split
max_leaf_nodes - stop growing the tree at a specified number of leaves
and others
4.1.1. Grid Search#
How do we explore this space? Suppose I want to try trees with these options:
max_depth = [4, 6, 8, 10, 12]
min_samples_split = [10, 20, 40]
How many models will I be testing?
GridSearch does just this in an automated way, testing every combination from the parameters you’d like to test.
max_depth |
min_samples_split |
Cartesian Product |
|---|---|---|
4 |
10 |
(4, 10) |
4 |
20 |
(4, 20) |
4 |
40 |
(4, 40) |
6 |
10 |
(6, 10) |
6 |
20 |
(6, 20) |
6 |
40 |
(6, 40) |
8 |
10 |
(8, 10) |
8 |
20 |
(8, 20) |
8 |
40 |
(8, 40) |
10 |
10 |
(10, 10) |
10 |
20 |
(10, 20) |
10 |
40 |
(10, 40) |
12 |
10 |
(12, 10) |
12 |
20 |
(12, 20) |
12 |
40 |
(12, 40) |
4.1.2. Cross-Validation#
Validation is used to select from a set of candidate models (e.g. different learning algorithms, variations on the same algorithm with different hyperparameters). In the simplest form of validation, we split off a portion of the training data and compare models based on their performance on this validation set. But more commonly, we use K-fold Cross-Validation:
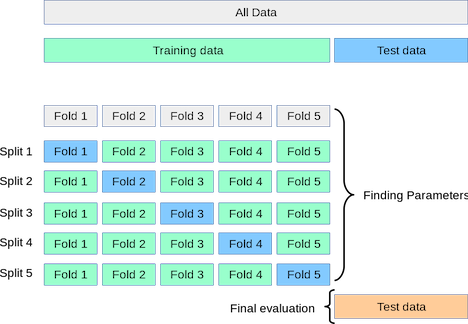
Split the training data into K “folds”
Set the first fold aside as a validation set and train on the remaining data.
Validate using that first fold as a validation set.
Repeat the process (K times in total), each time using a different fold as the validation set.
Average the performance across all the training-validation iterations.
4.1.3. Grid Search + Cross-Validation#
Grid Search and Cross-Validation are used in tandem so commonly that sklearn packages them together in some very convenient functions.
(some we’ve seen before)
4.2. Example: Palmer Penguins#
Let’s try to predict the species of penguins based on measured attributes.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import seaborn as sns
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.preprocessing import OneHotEncoder, OrdinalEncoder, LabelEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.model_selection import GridSearchCV, train_test_split
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.inspection import DecisionBoundaryDisplay
palmer = pd.read_csv('https://gist.githubusercontent.com/slopp/ce3b90b9168f2f921784de84fa445651/raw/4ecf3041f0ed4913e7c230758733948bc561f434/penguins.csv', index_col = 'rowid')
display(palmer.sample(10))
display(palmer.info())
display(palmer['species'].unique())
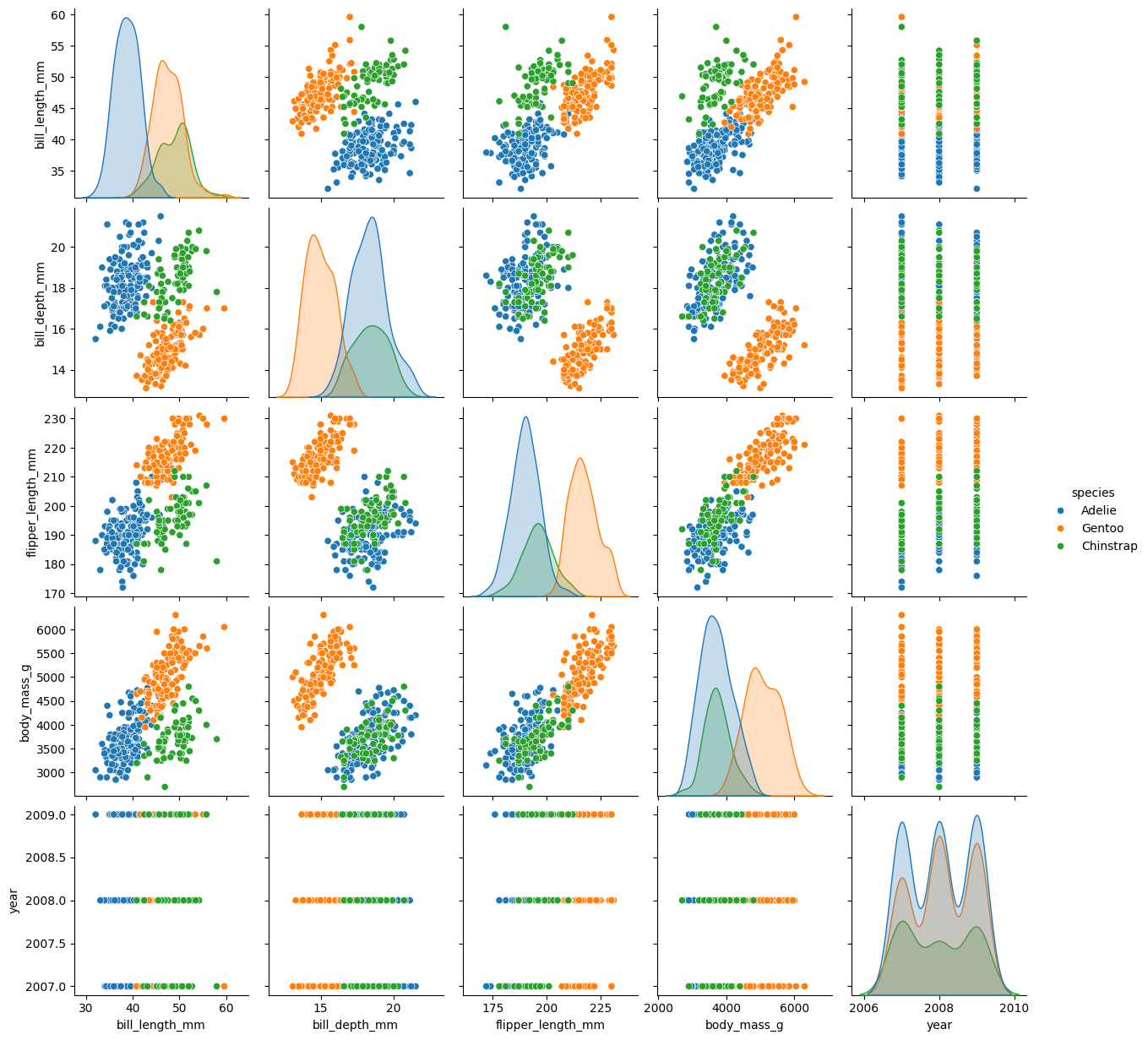
sns.pairplot(palmer, hue = 'species')
plt.show()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year | |
|---|---|---|---|---|---|---|---|---|
| rowid | ||||||||
| 181 | Gentoo | Biscoe | 48.2 | 14.3 | 210.0 | 4600.0 | female | 2007 |
| 262 | Gentoo | Biscoe | 48.1 | 15.1 | 209.0 | 5500.0 | male | 2009 |
| 236 | Gentoo | Biscoe | 50.0 | 15.9 | 224.0 | 5350.0 | male | 2009 |
| 342 | Chinstrap | Dream | 49.6 | 18.2 | 193.0 | 3775.0 | male | 2009 |
| 72 | Adelie | Torgersen | 39.7 | 18.4 | 190.0 | 3900.0 | male | 2008 |
| 47 | Adelie | Dream | 41.1 | 19.0 | 182.0 | 3425.0 | male | 2007 |
| 19 | Adelie | Torgersen | 34.4 | 18.4 | 184.0 | 3325.0 | female | 2007 |
| 172 | Gentoo | Biscoe | 48.7 | 15.1 | 222.0 | 5350.0 | male | 2007 |
| 68 | Adelie | Biscoe | 41.1 | 19.1 | 188.0 | 4100.0 | male | 2008 |
| 174 | Gentoo | Biscoe | 45.1 | 14.5 | 215.0 | 5000.0 | female | 2007 |
<class 'pandas.core.frame.DataFrame'>
Index: 344 entries, 1 to 344
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 species 344 non-null object
1 island 344 non-null object
2 bill_length_mm 342 non-null float64
3 bill_depth_mm 342 non-null float64
4 flipper_length_mm 342 non-null float64
5 body_mass_g 342 non-null float64
6 sex 333 non-null object
7 year 344 non-null int64
dtypes: float64(4), int64(1), object(3)
memory usage: 24.2+ KB
None
array(['Adelie', 'Gentoo', 'Chinstrap'], dtype=object)
# Prepare the data
palmer.dropna(axis = 0, inplace=True)
palmer.reset_index(drop = True, inplace=True)
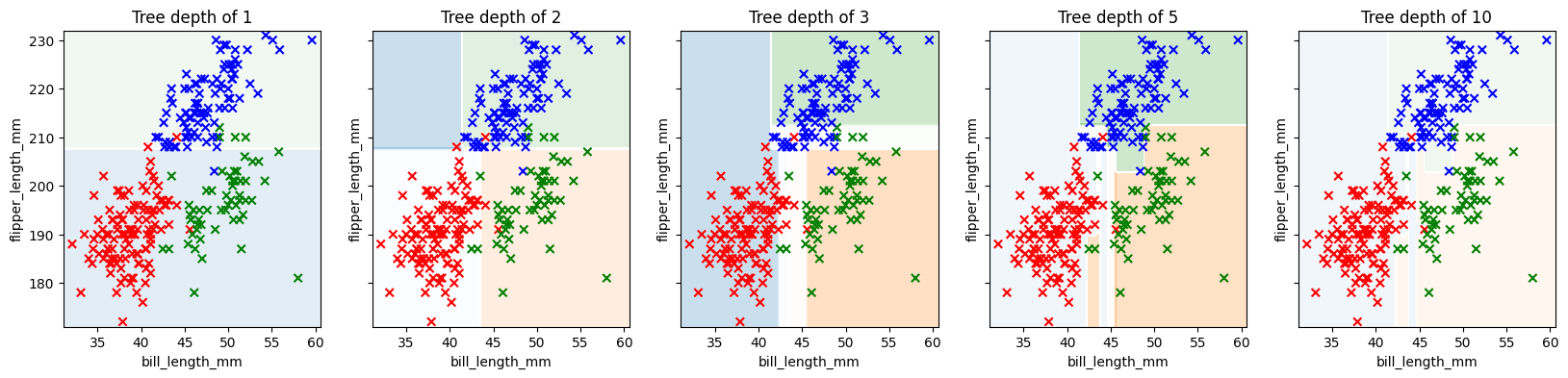
First, a quick visualization of how a decision tree slices up the feature space. For this visualization, we’ll select just two features.
Which two features would work well for predicting the species of the penguin?
features = ['bill_length_mm', 'flipper_length_mm']
target = ['species']
X = palmer[features]
y = LabelEncoder().fit_transform(palmer[target]).ravel()
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/preprocessing/_label.py:110: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
fig, axs = plt.subplots(1,5, figsize = (20,4), sharey = True)
for ax, depth in zip(axs, [1, 2, 3, 5, 10]):
tree_clf = DecisionTreeClassifier(max_depth=depth)
tree_clf.fit(X_train, y_train)
y_pred = tree_clf.predict(X_test)
cmap = ListedColormap(['red', 'green', 'blue']) # Training Data
DecisionBoundaryDisplay.from_estimator(
estimator = tree_clf, X = X,
cmap = cmap, alpha = 0.25,
ax = ax
)
## Training
ax.scatter(X_train.iloc[:,0], X_train.iloc[:,1],
c = y_train, cmap = cmap, marker = 'x')
# Testing Data
# ax.scatter(X_test.iloc[:,0], X_test.iloc[:,1],
# c = y_test, cmap = cmap, marker = '.')
ax.set_title(f'Tree depth of {depth}')
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/inspection/_plot/decision_boundary.py:226: UserWarning: 'cmap' is ignored in favor of 'multiclass_colors' in the multiclass case when the response method is 'decision_function' or 'predict_proba'.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/inspection/_plot/decision_boundary.py:226: UserWarning: 'cmap' is ignored in favor of 'multiclass_colors' in the multiclass case when the response method is 'decision_function' or 'predict_proba'.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/inspection/_plot/decision_boundary.py:226: UserWarning: 'cmap' is ignored in favor of 'multiclass_colors' in the multiclass case when the response method is 'decision_function' or 'predict_proba'.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/inspection/_plot/decision_boundary.py:226: UserWarning: 'cmap' is ignored in favor of 'multiclass_colors' in the multiclass case when the response method is 'decision_function' or 'predict_proba'.
warnings.warn(
/Users/eatai/.pyenv/versions/3.13.1/envs/datascience/lib/python3.13/site-packages/sklearn/inspection/_plot/decision_boundary.py:226: UserWarning: 'cmap' is ignored in favor of 'multiclass_colors' in the multiclass case when the response method is 'decision_function' or 'predict_proba'.
warnings.warn(
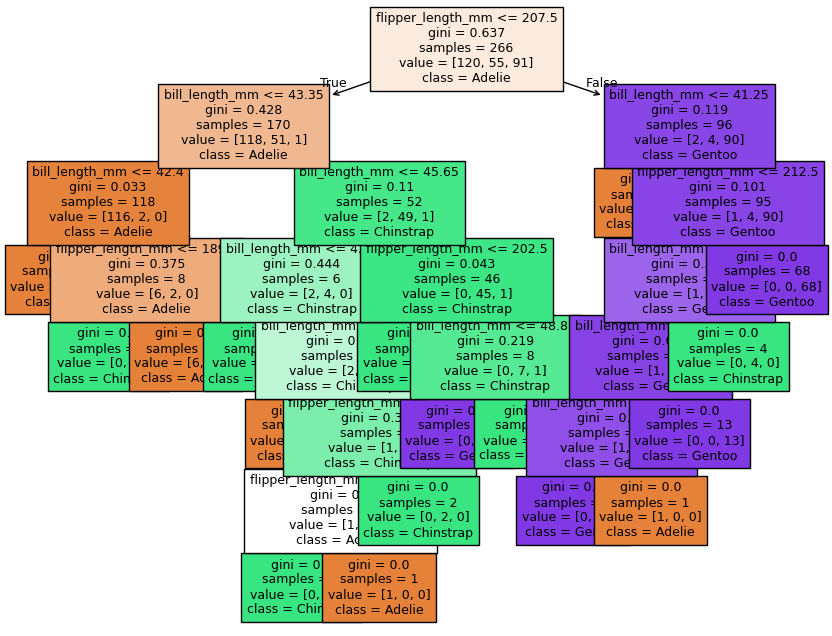
feature_names = tree_clf.feature_names_in_
label_names = ['Adelie', 'Chinstrap', 'Gentoo']
fig, ax = plt.subplots(1,1, figsize = (10, 8))
plot_tree(tree_clf,
filled = True, fontsize = 9,
feature_names = feature_names, class_names = label_names)
plt.show()
Now let’s find the best-fit tree for these data using GridsearchCV. Our modeling pipeline:
Select features and targets
Encode categorical data (tree methods don’t require scaling)
Specify candidate values for hyper-parameters
Fit GridSearchCV
Evaluate best-fit model
palmer.head()
| species | island | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | sex | year | |
|---|---|---|---|---|---|---|---|---|
| 0 | Adelie | Torgersen | 39.1 | 18.7 | 181.0 | 3750.0 | male | 2007 |
| 1 | Adelie | Torgersen | 39.5 | 17.4 | 186.0 | 3800.0 | female | 2007 |
| 2 | Adelie | Torgersen | 40.3 | 18.0 | 195.0 | 3250.0 | female | 2007 |
| 3 | Adelie | Torgersen | 36.7 | 19.3 | 193.0 | 3450.0 | female | 2007 |
| 4 | Adelie | Torgersen | 39.3 | 20.6 | 190.0 | 3650.0 | male | 2007 |
y = palmer[['species']]
X = palmer.drop(columns = 'species')
# Encode the data
cat_features = ['island']
oh = OneHotEncoder()
ord_features = ['sex']
ord = OrdinalEncoder(categories = [['male', 'female']])
ct = ColumnTransformer([
('oh', oh, cat_features),
('ord', ord, ord_features)],
remainder = 'passthrough',
verbose_feature_names_out = False
)
X = ct.fit_transform(X)
feature_names = ct.get_feature_names_out()
X_df = pd.DataFrame()
for k, fn in enumerate(feature_names):
X_df[fn] = X[:,k]
X_df.sample(10)
| island_Biscoe | island_Dream | island_Torgersen | sex | bill_length_mm | bill_depth_mm | flipper_length_mm | body_mass_g | year | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.0 | 0.0 | 1.0 | 1.0 | 39.5 | 17.4 | 186.0 | 3800.0 | 2007.0 |
| 7 | 0.0 | 0.0 | 1.0 | 1.0 | 41.1 | 17.6 | 182.0 | 3200.0 | 2007.0 |
| 165 | 1.0 | 0.0 | 0.0 | 0.0 | 48.7 | 15.1 | 222.0 | 5350.0 | 2007.0 |
| 321 | 0.0 | 1.0 | 0.0 | 1.0 | 45.2 | 16.6 | 191.0 | 3250.0 | 2009.0 |
| 287 | 0.0 | 1.0 | 0.0 | 1.0 | 43.2 | 16.6 | 187.0 | 2900.0 | 2007.0 |
| 259 | 1.0 | 0.0 | 0.0 | 0.0 | 48.8 | 16.2 | 222.0 | 6000.0 | 2009.0 |
| 187 | 1.0 | 0.0 | 0.0 | 1.0 | 45.3 | 13.7 | 210.0 | 4300.0 | 2008.0 |
| 152 | 1.0 | 0.0 | 0.0 | 1.0 | 45.4 | 14.6 | 211.0 | 4800.0 | 2007.0 |
| 131 | 0.0 | 1.0 | 0.0 | 0.0 | 40.2 | 20.1 | 200.0 | 3975.0 | 2009.0 |
| 113 | 0.0 | 0.0 | 1.0 | 0.0 | 41.1 | 18.6 | 189.0 | 3325.0 | 2009.0 |
X_train, X_test, y_train, y_test = train_test_split(X_df, y, test_size=0.2)
GridSearchCV requires three parameters:
an not-yet-fit instance of the desired model type (e.g. DecisionTreeClassifier, LogisticRegressionClassifier, etc)
a dictionary in which the keys are the hyper-parameter names and the corresponding values are a list of values you’d like to try for that hyper-parameter
the number of folds in your cross validation
tree_params = {
'max_depth': [2, 4, 6],
'min_samples_leaf': [2, 5, 10, 20],
'min_impurity_decrease': [.01, .1, .2, .5]
}
grid = GridSearchCV(DecisionTreeClassifier(),
tree_params, cv = 5
)
grid.fit(X_train, y_train)
GridSearchCV(cv=5, estimator=DecisionTreeClassifier(),
param_grid={'max_depth': [2, 4, 6],
'min_impurity_decrease': [0.01, 0.1, 0.2, 0.5],
'min_samples_leaf': [2, 5, 10, 20]})In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| estimator | DecisionTreeClassifier() | |
| param_grid | {'max_depth': [2, 4, ...], 'min_impurity_decrease': [0.01, 0.1, ...], 'min_samples_leaf': [2, 5, ...]} | |
| scoring | None | |
| n_jobs | None | |
| refit | True | |
| cv | 5 | |
| verbose | 0 | |
| pre_dispatch | '2*n_jobs' | |
| error_score | nan | |
| return_train_score | False |
DecisionTreeClassifier(max_depth=4, min_impurity_decrease=0.01,
min_samples_leaf=2)Parameters
| criterion | 'gini' | |
| splitter | 'best' | |
| max_depth | 4 | |
| min_samples_split | 2 | |
| min_samples_leaf | 2 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | None | |
| random_state | None | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.01 | |
| class_weight | None | |
| ccp_alpha | 0.0 | |
| monotonic_cst | None |
The grid object stores the info for all fit models, and we may choose to compare them at some point, but for now, we just want to get the best of the models it tested.
We can extract the best model using .best_estimator_.
Let’s evaluate and visualize our model.
tree2 = grid.best_estimator_
y_pred = tree2.predict(X_test)
cfm = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(cfm, display_labels = label_names).plot()
plt.show()
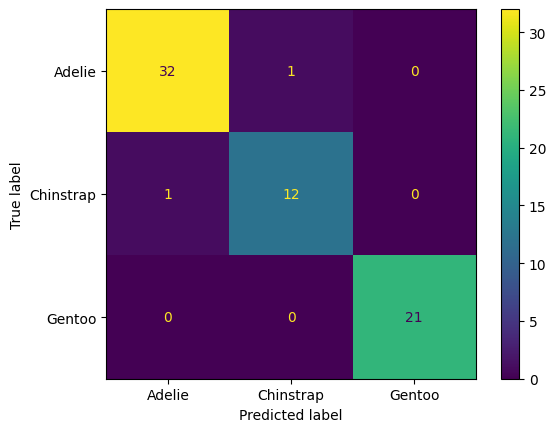
Interpret the confusion matrix above (for the test data). Which species get mistaken for other species?
Next, let’s investigate which features were most important. Generally, we think the features used higher up on the tree are the most informative features, since decision trees are trained by a greedy algorithm. But more specifically, the most informative features are the ones that are responsible for the greatest decrease in impurity.
We can get the importance of each feature using .feature_importances_.
Below we plot the decision tree and then print a list of features ordered by importance.
Compare that list to the structure of the tree. Does it make sense? What does it mean if a feature has 0 importance?
fig, ax = plt.subplots(1,1, figsize = (10, 6))
plot_tree(tree2,
filled = True, fontsize = 9,
feature_names = feature_names, class_names = label_names,
)
plt.show()
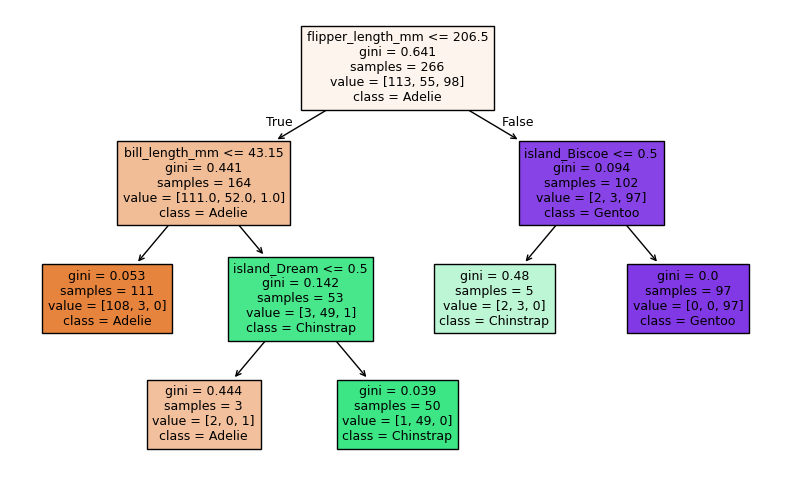
# Get feature importances and sort in decending order
idx = np.argsort(tree2.feature_importances_)[::-1]
# print importances
importances = tree2.feature_importances_[idx]
features = feature_names[idx]
for feature, imp in zip(features, importances):
print(f'{feature:_<30}{imp:.3f}')
flipper_length_mm_____________0.557
bill_length_mm________________0.371
island_Biscoe_________________0.045
island_Dream__________________0.027
year__________________________0.000
body_mass_g___________________0.000
bill_depth_mm_________________0.000
sex___________________________0.000
island_Torgersen______________0.000
4.3. Decision/Classification Tree Recap#
A decision tree classifies samples using a heirarchy of cascading conditional statements (yes-no questions about the sample).
In fitting a decision tree, at each node, a conditional statement is chosen so as to maximize the purity of the resultant split sub-samples.
Fitting a decision tree is deterministic. That is, given the same training data and hyper-parameters, you will arrive at the same tree.
There are challenges that come with real data that often cause problems for a decision tree:
High-dimensional data (many features)
Noisy data
Imbalanced class representation
We can improve on an individual decision tree by fitting numerous decision trees—an ensemble—and averaging/polling their results. There are two main categories of ensemble methods for decision trees, Random Forests and Boosted Trees, each with their own benefits and weaknesses.
5. Ensemble Methods (finally)#
5.1. Random Forests (RandomForestClassifier)#
A random forest creates numerous trees in parallel (at the same time). To make a prediction, a sample is processed by each tree, each tree makes a prediction, and the majority vote wins. But what makes the trees in the forest different from each other?
In fitting, diversity of trees is created using two methods: feature selection and bagging.
5.1.1. Random feature subsets#
Each tree only gets a subset of the features. For example, in a random forest deciding whether or not you should buy a car, one tree might make a prediction based on [‘reliability’, ‘feul economy’, ‘price’], while another uses [‘top speed’, ‘interior room’, ‘cost to repair’], and another uses [‘resale value’, ‘feul economy’, ‘value of standard tech’] and another…
5.1.2. Bagging (Bootstrap aggregating)#
Bootstrapping is a method for creating new data sets by sampling existing data sets. In bootstrapping, you select samples randomly and allow a sample to be selected multiple times (called sampling with replacement).
Bagging is a method that uses bootstrapping to create different training sets for each tree, and then aggregating the results.
The idea is that no one tree will be great, but they’ll all make different mistakes. But there’ll be more overlap in correct guesses than in mistakes. So for any given sample, the majority vote is more likely to be correct than any one tree.
5.2. Boosted Trees#
Whereas Random Forests fit trees in parallel and every tree gets an equal vote, Boosted trees create trees sequentially, each new tree focusing on the shortcomings of the previous. And at the voting stage, some trees get more say than others.
There are many flavors of Boosted trees: AdaBoost, XGBoost, CatBoost
They all work a little differently, but here’s an outline of AdaBoost as an example:
5.2.1. AdaBoost (Adaptive Boosting) ( GradientBoostingClassifier)#
In AdaBoost, a tree comprises only one decision node; this kind of tree is called a stump. In each iteration, a new stump is created that splits the data based on a different condition. As the algorithm iterates, it keeps track of:
Sample Weight - each iteration, the algorithm focuses more on misclassified samples.
A sample that is classified correctly is down-weighted. We get this right, don’t spend more energy on this case.
A sample that is classified incorrectly is up-weighted. We get this wrong, focus on this case.
Tree Influence - how much say a tree will have in the final vote. Trees that do better at classifying get more say.
A tree that is 50% correct gets no say. This tree is just guessing
A tree that is >50% gets a positive vote (0 to infinity). A tree that is 100% correct gets infinite vote! Listen to that tree!
A tree that is <50% gets a negative vote (0 to -infinity). A tree that is 0% correct gets a -infinite vote! Do the opposite of that tree!
The AdaBoost process:
Start with all the samples each counts the same.
Same as in a decision tree, pick a question that splits the data to minimize Gini Impurity.
Sum up sample weights for mis-classified samples and calculate Tree Influence.
Assign new weights to samples, increasing weights on mistakes and decreasing weights on correct classifications.
Create new stump, and repeat 2-5 until classification error is below some threshold you choose.
When you predict, you feed the sample through all the stumps and each votes according to their influence.
5.3. Some Pros and Cons#
5.3.1. Random Forests#
Pros:
Good for high-dimensional data
Good for noisy data
Easy to tune and fast to fit
Low variance (doesn’t over-fit data)
Cons:
Can be slow to run
5.3.2. Boosted Trees#
Pros:
Can get very accurate predictions (Low Bias)
Good for imbalanced data sets
Cons:
Prone to over-fitting
Susceptible to noise
Less interpretable