
3. Regularization#
When we explored Multiple Linear Regression, we tried to select features by inspecting correlations between a feature and the target as well as between features. But how did we know if we were using the right features and the right number of features? We didn’t.
Regularization is a tool for automatically emphasizing the features that are informative as you fit the model. Recall, in fitting linear regression models, we are minimizing the mean-squared error between our predictions and the true values. The cost function has the form:
Regularization adds a term to the cost function that penalizes large feature weights (\(\theta_i\)). Three common regularization algorithms for linear regression are:
Lasso regression (Least Absolute Shrinkage and Selection Operator):
Elastic Net (combines Ridge and Lasso)
Where
\(\alpha\) is a hyper-parameter that balances how much you want to balance model simplification and model fit.
L2 norm is the sum of squared values of weights
L1 norm is the sum of the absolute values of weights
\(r\) is a hyper-parameter in the range (0,1) that balances the amount of L2 (Ridge) and L1 (Lasso) penalty
That Ridge uses the L2-norm and Lasso uses the L1-norm can be reduced to the following observation:
Ridge regression will make some weights small, but not zero. This is useful if you believe many of the features contribute to the model.
Lasso regression will drive some weights to zero. This is useful if you believe only a few weights contribute.
However, we generally don’t know in advance how our features will contribute to the model, so best to try both and compare.
3.1. Why/when to use regularization?#
High-dimensional data. When number of features (p) is larger than the number of samples (n), linear regression (Ordinary Least Squares) fails.
Colinear features. Linear regression yields unstable coefficient estimates because multiple best-fit solutions exist.
Model over-fitting. Even when p<n, you may have too many parameters. That is, you’re using a model more complex than the data requires. (More about that next class!)
Feature selection. You want to build a model with fewer features.
3.2. Example: Baseball Salary Prediction (1986)#
import pandas as pd
pd.set_option('display.precision', 2)
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data_df = pd.read_csv('https://raw.githubusercontent.com/acakin/hitters/refs/heads/master/hitters.csv')
data_df
| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | CRuns | CRBI | CWalks | League | Division | PutOuts | Assists | Errors | Salary | NewLeague | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 293 | 66 | 1 | 30 | 29 | 14 | 1 | 293 | 66 | 1 | 30 | 29 | 14 | A | E | 446 | 33 | 20 | NaN | A |
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | 321 | 414 | 375 | N | W | 632 | 43 | 10 | 475.0 | N |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | 224 | 266 | 263 | A | W | 880 | 82 | 14 | 480.0 | A |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | 828 | 838 | 354 | N | E | 200 | 11 | 3 | 500.0 | N |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | 48 | 46 | 33 | N | E | 805 | 40 | 4 | 91.5 | N |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 317 | 497 | 127 | 7 | 65 | 48 | 37 | 5 | 2703 | 806 | 32 | 379 | 311 | 138 | N | E | 325 | 9 | 3 | 700.0 | N |
| 318 | 492 | 136 | 5 | 76 | 50 | 94 | 12 | 5511 | 1511 | 39 | 897 | 451 | 875 | A | E | 313 | 381 | 20 | 875.0 | A |
| 319 | 475 | 126 | 3 | 61 | 43 | 52 | 6 | 1700 | 433 | 7 | 217 | 93 | 146 | A | W | 37 | 113 | 7 | 385.0 | A |
| 320 | 573 | 144 | 9 | 85 | 60 | 78 | 8 | 3198 | 857 | 97 | 470 | 420 | 332 | A | E | 1314 | 131 | 12 | 960.0 | A |
| 321 | 631 | 170 | 9 | 77 | 44 | 31 | 11 | 4908 | 1457 | 30 | 775 | 357 | 249 | A | W | 408 | 4 | 3 | 1000.0 | A |
322 rows × 20 columns
data_df.dropna(inplace=True)
cat_features = ['League', 'Division', 'NewLeague']
league_df = pd.get_dummies(data_df[cat_features], dtype=int)
league_df
| League_A | League_N | Division_E | Division_W | NewLeague_A | NewLeague_N | |
|---|---|---|---|---|---|---|
| 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| 2 | 1 | 0 | 0 | 1 | 1 | 0 |
| 3 | 0 | 1 | 1 | 0 | 0 | 1 |
| 4 | 0 | 1 | 1 | 0 | 0 | 1 |
| 5 | 1 | 0 | 0 | 1 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... |
| 317 | 0 | 1 | 1 | 0 | 0 | 1 |
| 318 | 1 | 0 | 1 | 0 | 1 | 0 |
| 319 | 1 | 0 | 0 | 1 | 1 | 0 |
| 320 | 1 | 0 | 1 | 0 | 1 | 0 |
| 321 | 1 | 0 | 0 | 1 | 1 | 0 |
263 rows × 6 columns
hitters_df = data_df.drop(columns = cat_features).join(league_df)
hitters_df
| AtBat | Hits | HmRun | Runs | RBI | Walks | Years | CAtBat | CHits | CHmRun | ... | PutOuts | Assists | Errors | Salary | League_A | League_N | Division_E | Division_W | NewLeague_A | NewLeague_N | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 315 | 81 | 7 | 24 | 38 | 39 | 14 | 3449 | 835 | 69 | ... | 632 | 43 | 10 | 475.0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 2 | 479 | 130 | 18 | 66 | 72 | 76 | 3 | 1624 | 457 | 63 | ... | 880 | 82 | 14 | 480.0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 3 | 496 | 141 | 20 | 65 | 78 | 37 | 11 | 5628 | 1575 | 225 | ... | 200 | 11 | 3 | 500.0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 4 | 321 | 87 | 10 | 39 | 42 | 30 | 2 | 396 | 101 | 12 | ... | 805 | 40 | 4 | 91.5 | 0 | 1 | 1 | 0 | 0 | 1 |
| 5 | 594 | 169 | 4 | 74 | 51 | 35 | 11 | 4408 | 1133 | 19 | ... | 282 | 421 | 25 | 750.0 | 1 | 0 | 0 | 1 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 317 | 497 | 127 | 7 | 65 | 48 | 37 | 5 | 2703 | 806 | 32 | ... | 325 | 9 | 3 | 700.0 | 0 | 1 | 1 | 0 | 0 | 1 |
| 318 | 492 | 136 | 5 | 76 | 50 | 94 | 12 | 5511 | 1511 | 39 | ... | 313 | 381 | 20 | 875.0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 319 | 475 | 126 | 3 | 61 | 43 | 52 | 6 | 1700 | 433 | 7 | ... | 37 | 113 | 7 | 385.0 | 1 | 0 | 0 | 1 | 1 | 0 |
| 320 | 573 | 144 | 9 | 85 | 60 | 78 | 8 | 3198 | 857 | 97 | ... | 1314 | 131 | 12 | 960.0 | 1 | 0 | 1 | 0 | 1 | 0 |
| 321 | 631 | 170 | 9 | 77 | 44 | 31 | 11 | 4908 | 1457 | 30 | ... | 408 | 4 | 3 | 1000.0 | 1 | 0 | 0 | 1 | 1 | 0 |
263 rows × 23 columns
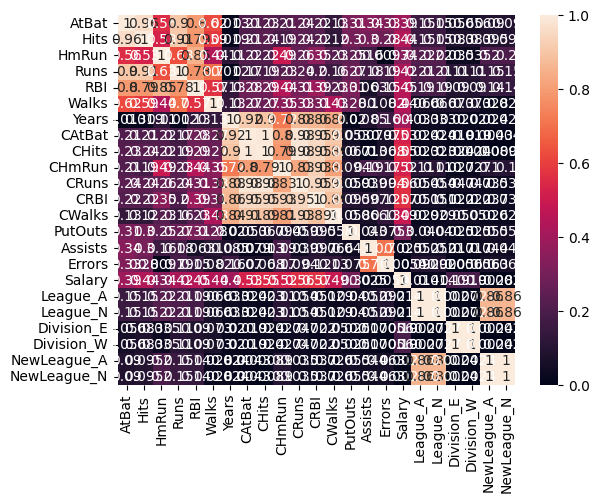
hitters_corr = hitters_df.corr()
sns.heatmap(np.abs(hitters_corr), vmin = 0, vmax = 1, annot = True)
<Axes: >
target = ['Salary']
y = hitters_df[target]
X = hitters_df.drop(columns = target)
features = list(X.columns)
features.append('intercept')
from sklearn.linear_model import LinearRegression, Ridge, Lasso, ElasticNet
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_regression
from sklearn.metrics import root_mean_squared_error, r2_score
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
sc = StandardScaler()
Z_train = sc.fit_transform(X_train)
Z_test = sc.transform(X_test)
linreg = LinearRegression()
linreg.fit(Z_train, y_train)
y_linreg_train = linreg.predict(Z_train)
y_linreg_test = linreg.predict(Z_test)
R2_linreg_train = r2_score(y_train, y_linreg_train)
R2_linreg_test = r2_score(y_test, y_linreg_test)
alpha = np.logspace(-2, 2, 9)
alpha
lasso_metrics = {}
ridge_metrics = {}
elnet_metrics = {}
lasso_coeffs = {}
lasso_coeffs['feature'] = features
ridge_coeffs = {}
ridge_coeffs['feature'] = features
elnet_coeffs = {}
elnet_coeffs['feature'] = features
for a in alpha:
print(f'Computing for alpha = {a:.3f}')
lasso = Lasso(alpha = a)
lasso.fit(Z_train, y_train)
lasso_coeffs[a] = np.append(lasso.coef_, lasso.intercept_)
y_lasso_train = lasso.predict(Z_train)
y_lasso_test = lasso.predict(Z_test)
lasso_metrics[a] = {'R2_train': r2_score(y_train, y_lasso_train),
'R2_test': r2_score(y_test, y_lasso_test),
'RMSE_train': root_mean_squared_error(y_train, y_lasso_train),
'RMSE_test': root_mean_squared_error(y_test, y_lasso_test)}
ridge = Ridge(alpha = a)
ridge.fit(Z_train, y_train)
ridge_coeffs[a] = np.append(ridge.coef_, ridge.intercept_)
y_ridge_train = ridge.predict(Z_train)
y_ridge_test = ridge.predict(Z_test)
ridge_metrics[a] = {'R2_train': r2_score(y_train, y_ridge_train),
'R2_test': r2_score(y_test, y_ridge_test),
'RMSE_train': root_mean_squared_error(y_train, y_ridge_train),
'RMSE_test': root_mean_squared_error(y_test, y_ridge_test)}
elnet = ElasticNet(alpha = a, l1_ratio = 0.5)
elnet.fit(Z_train, y_train)
elnet_coeffs[a] = np.append(elnet.coef_, elnet.intercept_)
y_elnet_train = elnet.predict(Z_train)
y_elnet_test = elnet.predict(Z_test)
elnet_metrics[a] = {'R2_train': r2_score(y_train, y_elnet_train),
'R2_test': r2_score(y_test, y_elnet_test),
'RMSE_train': root_mean_squared_error(y_train, y_elnet_train),
'RMSE_test': root_mean_squared_error(y_test, y_elnet_test)}
Computing for alpha = 0.010
Computing for alpha = 0.032
Computing for alpha = 0.100
Computing for alpha = 0.316
Computing for alpha = 1.000
Computing for alpha = 3.162
Computing for alpha = 10.000
Computing for alpha = 31.623
Computing for alpha = 100.000
lasso_df = pd.DataFrame(lasso_coeffs)
lasso_df.sort_values(by = 100.0, ascending = False)
| feature | 0.01 | 0.03 | 0.1 | 0.32 | 1.0 | 3.16 | 10.0 | 31.62 | 100.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 22 | intercept | 5.00e+02 | 5.00e+02 | 5.00e+02 | 5.00e+02 | 5.00e+02 | 5.00e+02 | 5.00e+02 | 500.13 | 500.13 |
| 10 | CRuns | 2.45e+02 | 2.50e+02 | 2.66e+02 | 2.78e+02 | 2.94e+02 | 2.45e+02 | 7.17e+01 | 89.21 | 124.40 |
| 1 | Hits | 1.02e+02 | 1.04e+02 | 1.08e+02 | 1.13e+02 | 1.22e+02 | 7.94e+01 | 7.77e+01 | 63.73 | 37.03 |
| 11 | CRBI | -6.84e+01 | -5.80e+01 | -2.62e+01 | 0.00e+00 | 5.32e+01 | 1.01e+02 | 6.31e+01 | 53.70 | 25.93 |
| 5 | Walks | 1.13e+02 | 1.13e+02 | 1.13e+02 | 1.14e+02 | 1.13e+02 | 9.50e+01 | 5.29e+01 | 44.83 | 21.40 |
| 13 | PutOuts | 9.34e+01 | 9.34e+01 | 9.33e+01 | 9.29e+01 | 9.24e+01 | 8.93e+01 | 8.34e+01 | 68.71 | 17.52 |
| 4 | RBI | 5.51e+01 | 5.36e+01 | 4.91e+01 | 4.49e+01 | 3.45e+01 | 1.14e+01 | 0.00e+00 | 1.82 | 1.05 |
| 7 | CAtBat | -5.19e+02 | -5.08e+02 | -4.76e+02 | -3.82e+02 | -1.33e+02 | -0.00e+00 | 0.00e+00 | 0.00 | 0.00 |
| 8 | CHits | 6.30e+02 | 6.10e+02 | 5.50e+02 | 4.42e+02 | 1.76e+02 | 2.64e+01 | 8.35e+01 | 59.72 | 0.00 |
| 9 | CHmRun | 9.61e+01 | 9.06e+01 | 7.39e+01 | 5.88e+01 | 2.85e+01 | 0.00e+00 | 0.00e+00 | 0.00 | 0.00 |
| 3 | Runs | -1.66e+01 | -1.71e+01 | -1.85e+01 | -1.85e+01 | -1.39e+01 | -0.00e+00 | 0.00e+00 | 0.00 | 0.00 |
| 2 | HmRun | -4.29e+01 | -4.19e+01 | -3.89e+01 | -3.67e+01 | -3.05e+01 | -1.72e+01 | -0.00e+00 | 0.00 | 0.00 |
| 12 | CWalks | -1.53e+02 | -1.54e+02 | -1.59e+02 | -1.66e+02 | -1.84e+02 | -1.51e+02 | -0.00e+00 | 0.00 | 0.00 |
| 6 | Years | -9.97e+00 | -1.02e+01 | -1.08e+01 | -1.45e+01 | -2.47e+01 | -1.22e+01 | -0.00e+00 | 0.00 | 0.00 |
| 14 | Assists | 5.02e+00 | 4.72e+00 | 3.80e+00 | 3.41e-01 | -3.73e+00 | -9.91e+00 | -9.34e+00 | -0.00 | -0.00 |
| 15 | Errors | -6.75e+00 | -6.55e+00 | -5.94e+00 | -4.31e+00 | -3.25e+00 | -1.51e+00 | -0.00e+00 | -0.00 | 0.00 |
| 16 | League_A | -5.13e+01 | -5.11e+01 | -5.04e+01 | -4.87e+01 | -4.34e+01 | -2.78e+01 | -1.38e+01 | -0.00 | -0.00 |
| 17 | League_N | 1.46e-11 | 1.32e-11 | 1.03e-11 | 7.61e-12 | 1.12e-11 | 2.60e-12 | 4.98e-13 | 0.00 | 0.00 |
| 18 | Division_E | 4.99e+01 | 4.99e+01 | 5.00e+01 | 5.01e+01 | 5.04e+01 | 5.02e+01 | 4.40e+01 | 22.17 | 0.00 |
| 19 | Division_W | -0.00e+00 | -0.00e+00 | -0.00e+00 | -0.00e+00 | -0.00e+00 | -0.00e+00 | -6.50e-15 | -0.00 | -0.00 |
| 20 | NewLeague_A | 3.38e+01 | 3.35e+01 | 3.25e+01 | 3.05e+01 | 2.43e+01 | 6.64e+00 | -0.00e+00 | -0.00 | -0.00 |
| 21 | NewLeague_N | -1.72e-12 | -6.15e-13 | -2.34e-13 | -7.46e-13 | -1.21e-13 | -0.00e+00 | 0.00e+00 | 0.00 | 0.00 |
| 0 | AtBat | -9.79e+01 | -9.81e+01 | -9.87e+01 | -1.00e+02 | -1.04e+02 | -3.94e+01 | 0.00e+00 | 0.00 | 0.00 |
ridge_df = pd.DataFrame(ridge_coeffs)
ridge_df.sort_values(by = 100.0, ascending = False)
| feature | 0.01 | 0.03 | 0.1 | 0.32 | 1.0 | 3.16 | 10.0 | 31.62 | 100.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 22 | intercept | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 |
| 13 | PutOuts | 93.41 | 93.44 | 93.46 | 93.20 | 92.21 | 90.16 | 86.58 | 78.82 | 61.98 |
| 8 | CHits | 625.44 | 571.63 | 459.22 | 313.47 | 206.11 | 148.57 | 108.27 | 72.67 | 48.57 |
| 10 | CRuns | 246.41 | 261.79 | 289.92 | 308.12 | 274.54 | 194.69 | 117.74 | 70.09 | 46.35 |
| 11 | CRBI | -68.20 | -48.28 | -8.78 | 34.23 | 52.90 | 60.18 | 63.68 | 54.23 | 41.20 |
| 5 | Walks | 112.83 | 113.96 | 116.18 | 118.19 | 115.95 | 104.50 | 82.35 | 57.87 | 40.91 |
| 1 | Hits | 103.15 | 109.37 | 121.80 | 134.83 | 133.35 | 109.39 | 76.51 | 53.69 | 39.36 |
| 7 | CAtBat | -515.05 | -480.58 | -403.61 | -282.51 | -147.20 | -37.58 | 18.73 | 33.80 | 33.47 |
| 9 | CHmRun | 96.01 | 85.28 | 64.16 | 41.98 | 34.72 | 34.36 | 32.22 | 30.45 | 28.01 |
| 3 | Runs | -17.04 | -19.50 | -23.96 | -26.49 | -19.26 | -2.02 | 14.05 | 22.08 | 24.54 |
| 4 | RBI | 55.22 | 52.74 | 47.84 | 42.50 | 40.10 | 38.64 | 34.92 | 28.13 | 23.25 |
| 18 | Division_E | 24.93 | 24.97 | 25.08 | 25.32 | 25.74 | 26.16 | 25.99 | 24.62 | 21.19 |
| 0 | AtBat | -98.55 | -101.86 | -108.59 | -115.77 | -112.62 | -86.11 | -39.79 | 0.41 | 18.73 |
| 17 | League_N | 25.69 | 25.58 | 25.35 | 25.04 | 24.72 | 24.00 | 21.74 | 16.95 | 11.09 |
| 6 | Years | -10.18 | -11.59 | -15.07 | -21.76 | -30.81 | -35.49 | -26.41 | -6.26 | 10.52 |
| 12 | CWalks | -153.41 | -159.00 | -170.22 | -182.14 | -180.76 | -153.80 | -99.44 | -38.04 | 2.07 |
| 21 | NewLeague_N | -16.93 | -16.72 | -16.32 | -15.95 | -15.91 | -15.43 | -12.56 | -6.35 | 0.37 |
| 20 | NewLeague_A | 16.93 | 16.72 | 16.32 | 15.95 | 15.91 | 15.43 | 12.56 | 6.35 | -0.37 |
| 15 | Errors | -6.76 | -6.42 | -5.71 | -4.77 | -4.14 | -4.17 | -4.82 | -5.67 | -5.17 |
| 14 | Assists | 5.01 | 4.41 | 2.94 | 0.02 | -4.76 | -10.99 | -16.17 | -16.07 | -10.64 |
| 2 | HmRun | -42.88 | -41.05 | -37.60 | -34.79 | -36.42 | -40.86 | -41.38 | -30.33 | -10.75 |
| 16 | League_A | -25.69 | -25.58 | -25.35 | -25.04 | -24.72 | -24.00 | -21.74 | -16.95 | -11.09 |
| 19 | Division_W | -24.93 | -24.97 | -25.08 | -25.32 | -25.74 | -26.16 | -25.99 | -24.62 | -21.19 |
elnet_df = pd.DataFrame(elnet_coeffs)
elnet_df.sort_values(by = 100.0, ascending = False)
| feature | 0.01 | 0.03 | 0.1 | 0.32 | 1.0 | 3.16 | 10.0 | 31.62 | 100.0 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 22 | intercept | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 | 500.13 |
| 10 | CRuns | 271.58 | 190.64 | 114.86 | 68.33 | 45.69 | 33.06 | 21.95 | 10.99 | 3.82 |
| 8 | CHits | 202.51 | 146.27 | 106.49 | 71.07 | 47.85 | 33.63 | 21.90 | 10.87 | 3.76 |
| 11 | CRBI | 53.22 | 60.42 | 63.54 | 53.42 | 40.68 | 30.93 | 21.04 | 10.63 | 3.69 |
| 7 | CAtBat | -141.17 | -33.35 | 19.54 | 33.47 | 33.34 | 28.39 | 20.06 | 10.25 | 3.55 |
| 9 | CHmRun | 34.69 | 34.28 | 31.96 | 30.08 | 27.69 | 24.70 | 18.19 | 9.43 | 3.25 |
| 12 | CWalks | -180.15 | -151.82 | -96.11 | -34.84 | 3.09 | 17.15 | 15.93 | 8.73 | 3.03 |
| 5 | Walks | 115.65 | 103.63 | 81.05 | 56.73 | 40.26 | 28.76 | 17.86 | 8.34 | 2.66 |
| 1 | Hits | 132.67 | 107.67 | 74.98 | 53.08 | 38.69 | 27.58 | 17.20 | 8.07 | 2.56 |
| 4 | RBI | 40.02 | 38.46 | 34.39 | 27.55 | 22.70 | 20.82 | 15.38 | 7.78 | 2.54 |
| 6 | Years | -31.18 | -35.37 | -25.28 | -4.66 | 10.81 | 16.58 | 13.95 | 7.48 | 2.51 |
| 3 | Runs | -18.59 | -1.02 | 14.36 | 22.21 | 24.28 | 21.99 | 15.30 | 7.46 | 2.37 |
| 0 | AtBat | -111.94 | -84.11 | -36.99 | 1.55 | 18.82 | 20.70 | 14.98 | 7.38 | 2.34 |
| 13 | PutOuts | 92.14 | 90.03 | 86.31 | 78.22 | 60.80 | 36.85 | 17.44 | 6.54 | 1.69 |
| 2 | HmRun | -36.58 | -40.97 | -40.86 | -28.93 | -8.92 | 4.78 | 8.28 | 4.93 | 1.53 |
| 18 | Division_E | 25.76 | 26.16 | 25.94 | 24.45 | 20.80 | 14.22 | 6.95 | 2.23 | 0.13 |
| 14 | Assists | -5.03 | -11.28 | -16.30 | -15.72 | -9.93 | -4.12 | -0.64 | -0.00 | -0.00 |
| 15 | Errors | -4.12 | -4.18 | -4.82 | -5.53 | -4.79 | -2.11 | -0.03 | -0.00 | -0.00 |
| 16 | League_A | -24.69 | -23.90 | -21.42 | -16.29 | -10.70 | -5.83 | -2.05 | -0.00 | -0.00 |
| 17 | League_N | 24.68 | 23.90 | 21.42 | 16.29 | 10.70 | 5.83 | 2.05 | 0.00 | 0.00 |
| 20 | NewLeague_A | 15.89 | 15.31 | 12.18 | 5.60 | -0.52 | -3.08 | -1.83 | -0.11 | -0.00 |
| 21 | NewLeague_N | -15.89 | -15.31 | -12.18 | -5.60 | 0.52 | 3.08 | 1.83 | 0.11 | 0.00 |
| 19 | Division_W | -25.75 | -26.16 | -25.94 | -24.45 | -20.80 | -14.22 | -6.95 | -2.23 | -0.13 |