9. Trees and Ensemble methods#
9.1. Decision/Classification Trees#
Tree-based models — Decision/Classification Trees and Regression Trees — are a family of algorithms that approach classification and regression using a heirarchy of conditional/if-else statements (imagine a flow chart or a game of 20 questions). You might describe tree-based models as human-like in their approach to problem solving. And these models are not only intuitive and interpretable, they are some of the most ubiquitous and powerful algorithms in ML.
We’ll start by looking at a cartoon example of a decision tree, this one predicts whether a casual golfer is expected to shoot below or above par on a given outing.
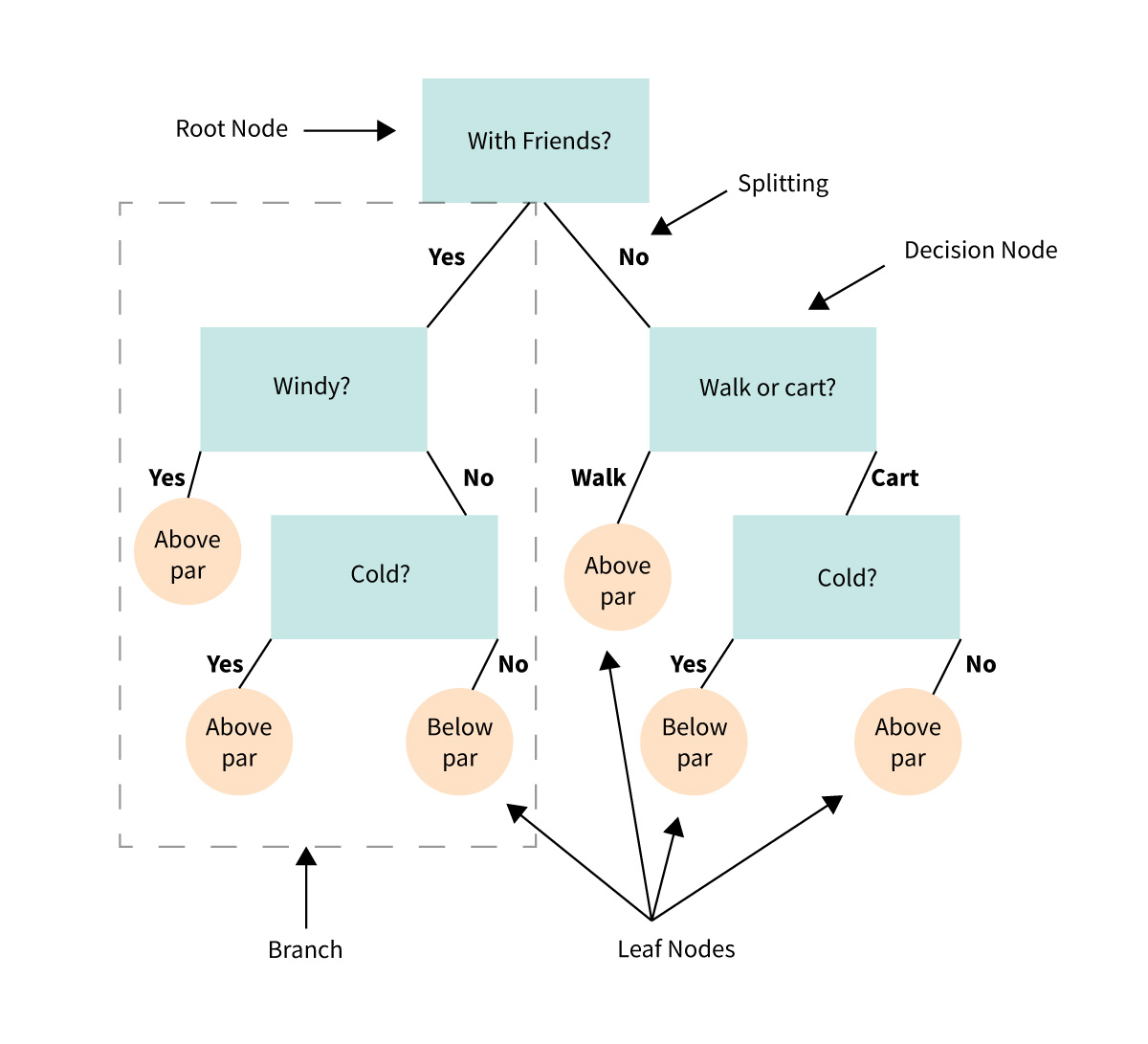
9.1.1. Anatomy of a tree#
Decision node - a binary question that divides the data set
Root node - the top decision node in the tree
Leaf node - a terminal node where the classification is made
Parent/Child node - the node before/after a split
Split - the forks off a node
Branch - all the decision and leaf nodes that spawn from a single up-stream decision
While the cartoon does a good job showing the structure and flow of a decision tree, it’s important to clarify an important detail about the nodes.
In the example, some of the nodes are truly categorical questions:
“With friends?”
“Walk or cart?”
While others are seemingly subjective. To make the subjective nodes binary, we define the question in terms of inequalities:
“Windy?” is ambiguous. Is 2 mph winds windy? 5 mph? 20 mph? Instead we would use an inequality on the feature: wind > 5 mph
“Cold?” is similarly ambiguous. So a node splitting on temperature would need to be formulated as an inequality: temp < 50 F
9.1.2. How do we choose what a good condition for a node would be?#
It is preferable for tree-models to have fewer nodes; smaller models are better. And ideally, each leaf node would represent a set of samples that all belonged to the same class, that is to say, if you followed the branches down to that leaf node, your classification would be correct (and this is not always possible).
Intuitively, what questions might you ask to classify:
animals into their classes: Mammals, Birds, Reptiles, Amphibians, and Fish.
beers into their types: pilsner, lager, ale, porter, stout
movies into hits or flops
voters into their political leanings: Liberal, Conservative, Libertarian, Populist, etc.
Towards this ideal, at each node, we would want a conditional statement that split the set in a way so that the resulting subsets are as homogeneous (mostly or all one class) as possible. This homogeneity is referred to as the “purity” of the node, and there are different ways of quantifying said purity: Gini Impurity and Information Gain.
9.1.3. Gini Impurity#
Gini impurity is the likelihood of randomly misclassifying a randomly selected sample given the distribution of samples in the set; that is, if you randomly select a sample and randomly select a label, Gini impurity is the likelihood of a mismatch. A Gini impurity of zero represents a perfectly homogeneous set (all the same class).
If using Gini impurity as the criterion, the fitting algorithm will choose conditions to minimize the Gini impurity at each successive split (using a greedy algorithm).
The Gini index for a sub-node is:
where:
\(i\) is the class index
\(M\) is the number of classes
\(p_i\) is the proportion of a given class in the subset.
The Gini impurity for a split is the sum of the Gini index for each resultant node, weighted by the number of samples in each node.
where:
\(N\) is the sample size at the parent node
\(n_k\) is the sample size at each sub-node
Example: Dogs, Cat, Mouse classifier.
9.2. Information Gain#
Entropy in physics quantifies dis-order. Analagously, entropy in information theory quantifies uncertainty.
Entropy (H) of a set is defined as:
What is the entropy if \(p_i = 0\) or \(p_i = 1\)?
When entropy is zero, there is no uncertainity; in the case of a decision tree, the subsample is perfectly homogeneous.
Information gain is the reduction of entropy between the parent and child node.
If using Information Gain as the criterion, the fitting algorithm will choose conditions to maximize Information Gain (reduce entropy) at each successive split (using a greedy algorithm).
9.3. Example: Drug prescriptions#
For this example, we’ll be looking at the drug200 data set (https://www.kaggle.com/datasets/prathamtripathi/drug-classification).
The dataset summarizes the demographics and health condition of 200 patients (Age, sex, blood, pressure, cholesterol, and sodium/potassium ratio) as well as which of five drugs had best results with the patient. The goal is to build a classifier to choose which drug to prescribe to a future patient.
import pandas as pd
drugs_df = pd.read_csv('https://raw.githubusercontent.com/kvinlazy/Dataset/refs/heads/master/drug200.csv')
drugs_df
| Age | Sex | BP | Cholesterol | Na_to_K | Drug | |
|---|---|---|---|---|---|---|
| 0 | 23 | F | HIGH | HIGH | 25.355 | drugY |
| 1 | 47 | M | LOW | HIGH | 13.093 | drugC |
| 2 | 47 | M | LOW | HIGH | 10.114 | drugC |
| 3 | 28 | F | NORMAL | HIGH | 7.798 | drugX |
| 4 | 61 | F | LOW | HIGH | 18.043 | drugY |
| ... | ... | ... | ... | ... | ... | ... |
| 195 | 56 | F | LOW | HIGH | 11.567 | drugC |
| 196 | 16 | M | LOW | HIGH | 12.006 | drugC |
| 197 | 52 | M | NORMAL | HIGH | 9.894 | drugX |
| 198 | 23 | M | NORMAL | NORMAL | 14.020 | drugX |
| 199 | 40 | F | LOW | NORMAL | 11.349 | drugX |
200 rows × 6 columns
9.3.1. Transform (Encode) the data#
y = drugs_df['Drug']
X = drugs_df.drop(columns = 'Drug')
X
| Age | Sex | BP | Cholesterol | Na_to_K | |
|---|---|---|---|---|---|
| 0 | 23 | F | HIGH | HIGH | 25.355 |
| 1 | 47 | M | LOW | HIGH | 13.093 |
| 2 | 47 | M | LOW | HIGH | 10.114 |
| 3 | 28 | F | NORMAL | HIGH | 7.798 |
| 4 | 61 | F | LOW | HIGH | 18.043 |
| ... | ... | ... | ... | ... | ... |
| 195 | 56 | F | LOW | HIGH | 11.567 |
| 196 | 16 | M | LOW | HIGH | 12.006 |
| 197 | 52 | M | NORMAL | HIGH | 9.894 |
| 198 | 23 | M | NORMAL | NORMAL | 14.020 |
| 199 | 40 | F | LOW | NORMAL | 11.349 |
200 rows × 5 columns
drugs_df['Cholesterol'].unique()
array(['HIGH', 'NORMAL'], dtype=object)
from sklearn.preprocessing import OrdinalEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
ord_features = ['Sex', 'BP', 'Cholesterol']
sex = ['M', 'F']
BP = ['LOW', 'NORMAL', 'HIGH']
Chol = ['NORMAL', 'HIGH']
ordenc = OrdinalEncoder(categories = [sex, BP, Chol])
num_features = ['Age', 'Na_to_K']
sc = StandardScaler()
coltrans = ColumnTransformer(
transformers = [
('ordinal', ordenc, ord_features),
('numerical', sc, num_features)
],
remainder = 'drop',
verbose_feature_names_out= False
)
X_trans = coltrans.fit_transform(X)
feature_names = coltrans.get_feature_names_out()
X_df = pd.DataFrame(X_trans, columns = feature_names)
X_df
| Sex | BP | Cholesterol | Age | Na_to_K | |
|---|---|---|---|---|---|
| 0 | 1.0 | 2.0 | 1.0 | -1.291591 | 1.286522 |
| 1 | 0.0 | 0.0 | 1.0 | 0.162699 | -0.415145 |
| 2 | 0.0 | 0.0 | 1.0 | 0.162699 | -0.828558 |
| 3 | 1.0 | 1.0 | 1.0 | -0.988614 | -1.149963 |
| 4 | 1.0 | 0.0 | 1.0 | 1.011034 | 0.271794 |
| ... | ... | ... | ... | ... | ... |
| 195 | 1.0 | 0.0 | 1.0 | 0.708057 | -0.626917 |
| 196 | 0.0 | 0.0 | 1.0 | -1.715759 | -0.565995 |
| 197 | 0.0 | 1.0 | 1.0 | 0.465676 | -0.859089 |
| 198 | 0.0 | 1.0 | 0.0 | -1.291591 | -0.286500 |
| 199 | 1.0 | 0.0 | 0.0 | -0.261469 | -0.657170 |
200 rows × 5 columns
9.3.2. Fit a decision tree model#
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_df, y, test_size= 0.2, random_state = 42)
tree_clf = DecisionTreeClassifier(
max_depth = 4,
min_samples_split = 10
)
tree_clf.fit(X_train, y_train)
DecisionTreeClassifier(max_depth=4, min_samples_split=10)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| criterion | 'gini' | |
| splitter | 'best' | |
| max_depth | 4 | |
| min_samples_split | 10 | |
| min_samples_leaf | 1 | |
| min_weight_fraction_leaf | 0.0 | |
| max_features | None | |
| random_state | None | |
| max_leaf_nodes | None | |
| min_impurity_decrease | 0.0 | |
| class_weight | None | |
| ccp_alpha | 0.0 | |
| monotonic_cst | None |
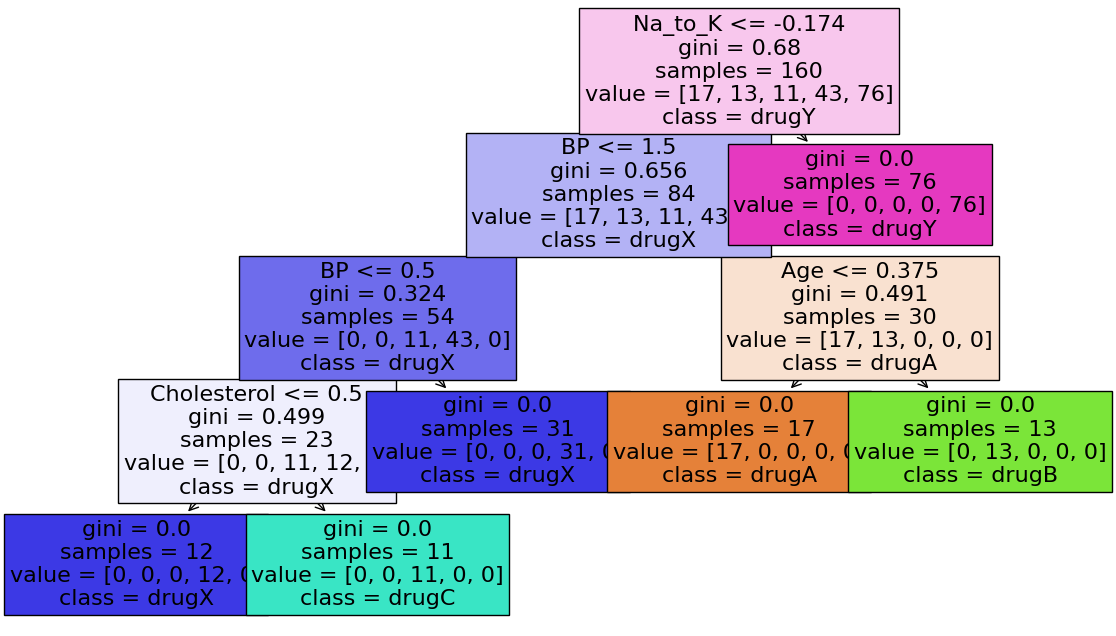
import matplotlib.pyplot as plt
label_names = ['drugA', 'drugB', 'drugC', 'drugX', 'drugY']
fig, ax = plt.subplots(1,1, figsize = (14, 8))
plot_tree(tree_clf,
filled = True, fontsize = 16,
feature_names = feature_names,
class_names = label_names)
plt.show()
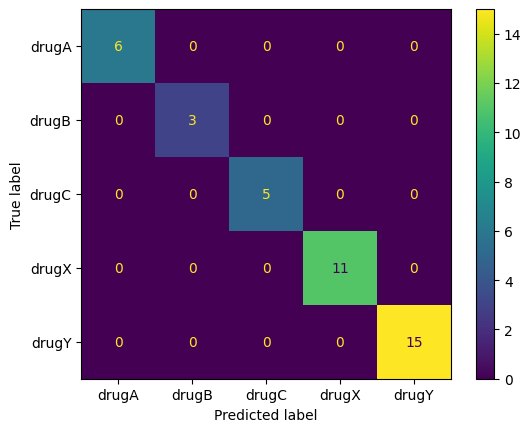
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
y_test_pred = tree_clf.predict(X_test)
ConfusionMatrixDisplay.from_predictions(y_test, y_test_pred)
plt.show()