
4. Polynomial Regression#
…because nothing in this world is truly linear.
Sometimes our data just aren’t linear. We can extend the linear regression approach to fitting ‘curvy’ data in several ways (e.g. we fit an exponential curve on PS1). Today we’ll introduce polynomial regression.
4.1. What is a polynomial?#
An equation composed of variables, variables raised to powers (e.g. squared, cubed, etc), and/or the product of variables and variables raised to powers.
Examples:
\(y = x^2\)
\(y = 5 x^3 + 4.5^x - 3.6\)
\(y = x_1^2 + 3.7 x_1 x_2 +2.1 x_2^2\)
And Taylor’s theorem tells us that any smooth curve can be approximated within some range arbitrarily closely by some polynomial (if you took calculus, this is the foundation of the Taylor Series).
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-5, 5, 0.01)
y = np.sin(x) + np.cos(1.7 * x)
y1 = 1 + x
y2 = y1 - 1.445 * x**2
y3 = y2 - 1.667 * x**3
y8 = y3 + 0.3480041667 * x**4 \
+ 0.0083333333 * x**5 \
- 0.0335244014 * x**6 \
- 0.0001984127 * x**7 \
+ 0.0017300986 * x**8 \
y14 = 1.0 \
+ 1.0 * x \
- 1.445 * x**2 \
- 0.1666666667 * x**3 \
+ 0.3480041667 * x**4 \
+ 0.0083333333 * x**5 \
- 0.0335244014 * x**6 \
- 0.0001984127 * x**7 \
+ 0.0017300986 * x**8 \
+ 0.0000027557 * x**9 \
- 0.0000555554 * x**10 \
- 0.0000000251 * x**11 \
+ 0.0000012163 * x**12 \
+ 0.0000000002 * x**13 \
- 0.0000000193 * x**14 \
fig, ax = plt.subplots(1,5, figsize = (15, 3), sharex = True, sharey = True)
ax[0].plot(x, y, 'k', linewidth = 2)
ax[0].plot(x, y1, 'r--', label = '1st order')
ax[0].text(.2, 2, '1st order', fontsize = 13)
ax[1].plot(x, y, 'k', linewidth = 2)
ax[1].plot(x, y2, 'r--', label = '2nd order')
ax[1].text(.2, 2, '2nd order', fontsize = 13)
ax[2].plot(x, y, 'k', linewidth = 2)
ax[2].plot(x, y3, 'r--', label = '3rd order')
ax[2].text(.2, 2, '3rd order', fontsize = 13)
ax[3].plot(x, y, 'k', linewidth = 2)
ax[3].plot(x, y8, 'r--', label = '8th order')
ax[3].text(.2, 2, '8th order', fontsize = 13)
ax[4].plot(x, y, 'k', linewidth = 2)
ax[4].plot(x, y14, 'r--', label = '14th order')
ax[4].text(.2, 2, '14th order', fontsize = 13)
plt.ylim([-2.5, 2.5])
plt.show()
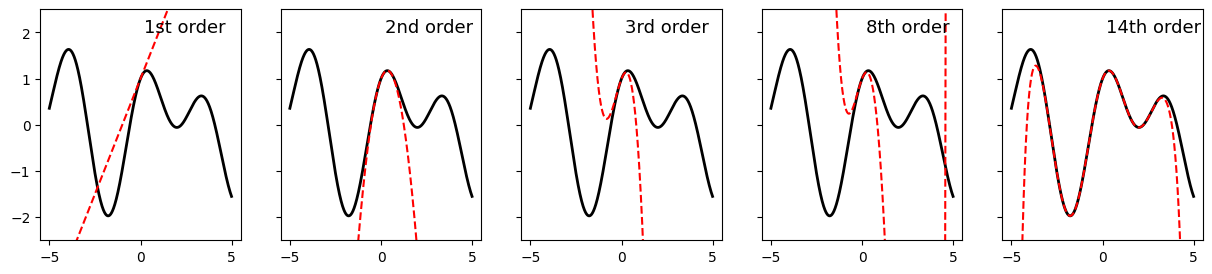
4.2. But polynomials aren’t linear!#
True.
So we’re going to create new features from which we can build a polynomial and our equation will be linear with regards to these new features. Whenever we create new features from existing features, we call that feature engineering.
Take for example the polynomial expression:
Now let’s make a new set of features:
Now substituting our new variables into our polynomial:
This equation is linear with respect to our new features (\(z_1, z_2, z_3\)), so we can use linear regression to find the best fit coeffecients!
4.2.1. Engineering Polynomial features#
Scikit-learn provides a function PolynomialFeatures that creates new polynomial features from our existing features. Let’s examine this function.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
X = np.array([1,2,3]).reshape(-1,1)
poly = PolynomialFeatures(degree=5, include_bias = False)
V = poly.fit_transform(X)
Notice, each column corresponds to one of our new features.
4.2.2. Creating some curvy synthetic data#
num_samples = 80
# Define polynomial coefficients for two different polynomials
poly_coeff = [-0.5, -4.2, 0, 0.9, 2]
my_poly = lambda z: np.polyval(poly_coeff, z) # Polynomial function: -0.5*z^4 - 4.2*z^3 + 0.9*z + 2
# Generate random x data points
np.random.seed(98)
x = np.sort(np.linspace(-1, 1, num_samples) + np.random.normal(scale=0.1, size=num_samples))
# Plug the x data points into the polynomial function and add some noise
y = my_poly(x) + np.random.normal(loc=0, scale=0.5, size=num_samples)
# x_range is an array of data points in the x direction. y_range is the polynomial plotted over that range.
# These will be used to display the models.
x_range = np.linspace(-1, 1, 100).reshape(-1, 1)
y_range = my_poly(x_range)
# Plot the data points and polynomial curves
plt.scatter(x, y, s=10)
plt.plot(x_range, y_range, 'r--')
# Get y-axis limits for the plot
my_ylims = plt.gca().get_ylim()
plt.show()
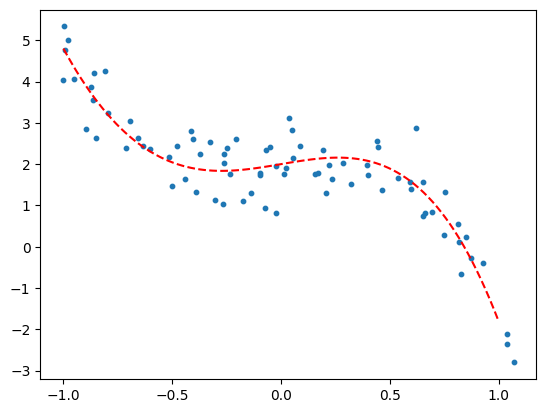
4.2.3. Fitting the models#
Suppose we were presented the data above, not having made it ourselves. How would we know what degree of polynomial to use? We wouldn’t.
So, we’re going to fit polynomials of different degrees and inspect the results. We’ll also fit Lasso, Ridge, and Elastic Net models to the data.
Linear Regression with polynomial features up to degree 1, 2, 4, 8, and 16
Lasso, Ridge, and Elastic Net with polynomial features up to degree 16 (we’ll let regularization decide what stays and what goes)
## Linear Regressions
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
# Split the data into training and testing sets
x_train, x_test, y_train, y_test = train_test_split(x.reshape(-1,1), y,
test_size = 0.5)
# Define the degrees of the polynomial features to be tested
degs = [1, 2, 4, 8, 16]
# Initialize a dictionary to store the models
models = {}
# Loop over each degree
for deg in degs:
# Create polynomial features
poly = PolynomialFeatures(degree=deg, include_bias=False)
V_train = poly.fit_transform(x_train)
V_test = poly.transform(x_test)
v_names = poly.get_feature_names_out()
# Standardize the features
ss = StandardScaler()
Z_train = ss.fit_transform(V_train)
Z_test = ss.transform(V_test)
# Train a linear regression model on the scaled polynomial features
reg_poly = LinearRegression()
reg_poly.fit(Z_train, y_train)
# Transform the x_range using the polynomial features and the scaler
# These aren't data, they're x- and y-values used to plot the model
z_model = ss.transform(poly.transform(x_range))
y_model = reg_poly.predict(z_model)
# Calculate the R^2 score for training and testing sets
R2_train = reg_poly.score(Z_train, y_train)
R2_test = reg_poly.score(Z_test, y_test)
# Store the model and its details in the dictionary
key = f'Poly_{deg}'
models[key] = dict(
title = f'Poly {deg}',
feature_names = v_names,
scaler = ss,
model = reg_poly,
z_model = z_model,
y_model = y_model,
R2_train = R2_train,
R2_test = R2_test
)
## Lasso
from sklearn.linear_model import LassoCV, RidgeCV, ElasticNetCV
alpha_test = np.logspace(-2,3,51)
lasso_poly = LassoCV(alphas = alpha_test)
lasso_poly.fit(Z_train, y_train)
y_model = lasso_poly.predict(z_model)
R2_train = lasso_poly.score(Z_train, y_train)
R2_test = lasso_poly.score(Z_test, y_test)
models['lasso'] = dict(
title = f'Lasso (alpha:{lasso_poly.alpha_:0.2f})',
params = lasso_poly.alpha_,
feature_names = v_names,
scaler = ss,
model = lasso_poly,
y_model = y_model,
R2_train = R2_train,
R2_test = R2_test
)
## Ridge
ridge_poly = RidgeCV(alphas = alpha_test)
ridge_poly.fit(Z_train, y_train)
y_model = ridge_poly.predict(z_model)
R2_train = ridge_poly.score(Z_train, y_train)
R2_test = ridge_poly.score(Z_test, y_test)
models['ridge'] = dict(
title = f'Ridge (alpha:{ridge_poly.alpha_:0.2f})',
params = ridge_poly.alpha_,
feature_names = v_names,
model = ridge_poly,
scaler = ss,
y_model = y_model,
R2_train = R2_train,
R2_test = R2_test
)
## Elastic Net
l1_ratio_test = [0.1, 0.25, 0.5, 0.75, 0.9]
elastic_poly = ElasticNetCV(alphas = alpha_test, l1_ratio = l1_ratio_test)
elastic_poly.fit(Z_train, y_train)
y_model = elastic_poly.predict(z_model)
R2_train = elastic_poly.score(Z_train, y_train)
R2_test = elastic_poly.score(Z_test, y_test)
models['elastic'] = dict(
title = f'Elastic Net (alpha:{elastic_poly.alpha_:0.2f}, l1:{elastic_poly.l1_ratio_:0.2f}',
params = [elastic_poly.alpha_, elastic_poly.l1_ratio_],
feature_names = v_names,
scaler = ss,
model = elastic_poly,
y_model = y_model,
R2_train = R2_train,
R2_test = R2_test
)
4.2.4. Displaying the model results#
fig,ax = plt.subplots(len(models), 2, figsize = (10,30), sharex=True, sharey=True)
x_range = np.linspace(-1,1,100).reshape(-1,1)
y_true = my_poly(x_range)
for k, key in enumerate(models):
reg = models[key]
ax[k,0].scatter(x_train, y_train, s=10, color = 'teal')
ax[k,0].plot(x_range, reg['y_model'], 'k--')
ax[k,0].plot(x_range, y_range, 'r--', alpha = 0.3)
ax[k,0].text(0.5,0.8, f'{reg['title']}\n$R^2 = ${reg["R2_train"]:.2}', transform=ax[k,0].transAxes)
ax[k,0].set_ylim(my_ylims)
ax[k,1].scatter(x_test, y_test, s=10, color = 'goldenrod')
ax[k,1].plot(x_range, y_range, 'r--', alpha = 0.3)
ax[k,1].plot(x_range, reg['y_model'], 'k--')
ax[k,1].text(0.5,0.8, f'$R^2 = ${reg["R2_test"]:.2}', transform=ax[k,1].transAxes)
ax[0,0].set_title('Training Set')
ax[0,1].set_title('Testing Set')
plt.show()
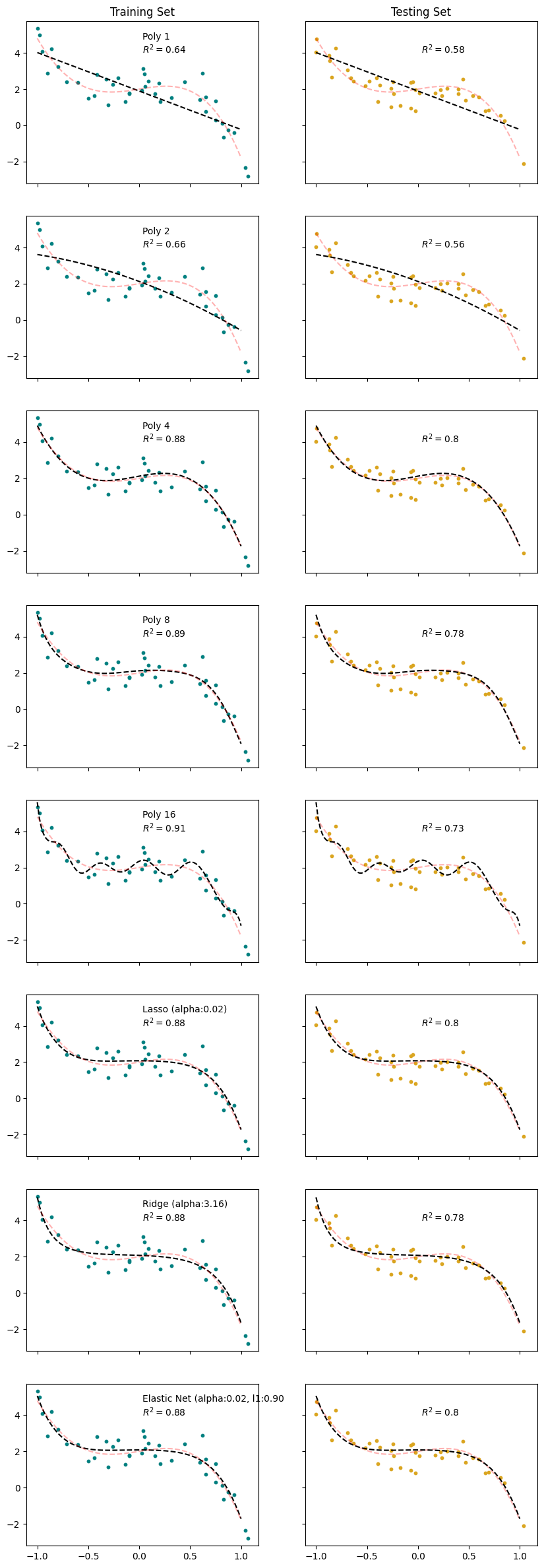
# When we fit our model with standardized features, the coefficients we solve for are with respect to the scaled features
# This function converts the parameters back to the scale of the original features (before standardization)
def unscale_coefs(scaler, coef, intercept = 0):
sc = np.array(scaler.scale_)
me = np.array(scaler.mean_)
coef_unsc = np.true_divide(coef, sc)
intercept_unsc = intercept - np.dot(coef_unsc, me)
return coef_unsc, intercept_unsc
# A function to create a string of the equation of a model
def model_string(model = None, intercept=0, coef = [], X_names = [], model_name = None):
# A function to print the equation of a linear model
if model is not None:
intercept = model.intercept_
coef = model.coef_
if model_name is None:
model_str = f'y ='
else:
model_str = f'{model_name}:\n y ='
if not intercept==0:
model_str += f' {intercept:.2f}'
for c, x in zip(coef, X_names):
if np.isclose(c,0):
continue
elif c<0:
model_str+= f' - {-c:.2f}*{x}'
else:
model_str+= f' + {c:.2f}*{x}'
return(model_str)
import warnings
warnings.filterwarnings('ignore')
coeff_df = pd.DataFrame()
nans = [np.nan]*17
coeff_df['True'] = nans
coeff_df['True'].iloc[np.arange(len(poly_coeff))] = poly_coeff[-1::-1]
model_eqs = []
for k, key in enumerate(models):
reg = models[key]
title = reg['title']
coefs_unscaled, intercept_unscaled = unscale_coefs(reg['scaler'], reg['model'].coef_, reg['model'].intercept_)
coeffs = np.concatenate((np.array([intercept_unscaled]), coefs_unscaled))
coeff_df[title] = nans
coeff_df[title].iloc[np.arange(len(coeffs))] = coeffs
# Model strings with scaled model parameters
# model_str = model_string(model = reg['model'], X_names = reg['feature_names'], model_name = reg['title'])
# Model strings with un-scaled model parameters
model_str = model_string(coef=coefs_unscaled, intercept=intercept_unscaled, X_names = reg['feature_names'], model_name = reg['title'])
model_eqs.append(model_str)
true_model_eq = model_string(coef = poly_coeff[-2::-1], intercept = poly_coeff[-1], X_names = reg['feature_names'], model_name = 'True model')
model_eqs.append(true_model_eq)
pd.options.display.float_format = '{:.2f}'.format
coeff_df.fillna('')
| True | Poly 1 | Poly 2 | Poly 4 | Poly 8 | Poly 16 | Lasso (alpha:0.02) | Ridge (alpha:3.16) | Elastic Net (alpha:0.02, l1:0.90 | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.00 | 1.89 | 2.12 | 2.12 | 2.12 | 2.35 | 2.08 | 2.08 | 2.08 |
| 1 | 0.90 | -2.12 | -2.10 | 1.02 | 0.38 | 2.63 | -0.00 | -0.21 | 0.00 |
| 2 | 0.00 | -0.61 | -0.57 | -1.26 | -26.64 | -0.49 | -0.39 | -0.50 | |
| 3 | -4.20 | -4.35 | -1.71 | -91.67 | -0.73 | -0.91 | -0.78 | ||
| 4 | -0.50 | 0.04 | 4.88 | 406.72 | -0.00 | -0.27 | -0.00 | ||
| 5 | -1.95 | 845.30 | -2.67 | -0.89 | -2.61 | ||||
| 6 | -9.75 | -2567.79 | 0.00 | -0.15 | -0.00 | ||||
| 7 | -0.27 | -3314.14 | -0.00 | -0.65 | -0.00 | ||||
| 8 | 5.66 | 8352.32 | 0.00 | -0.01 | 0.00 | ||||
| 9 | 6567.95 | -0.00 | -0.40 | -0.00 | |||||
| 10 | -15246.20 | 0.00 | 0.08 | 0.00 | |||||
| 11 | -7029.38 | -0.00 | -0.23 | -0.00 | |||||
| 12 | 15772.43 | 0.00 | 0.14 | 0.00 | |||||
| 13 | 3911.09 | -0.00 | -0.12 | -0.00 | |||||
| 14 | -8640.13 | 0.00 | 0.17 | 0.00 | |||||
| 15 | -895.20 | -0.00 | -0.06 | -0.00 | |||||
| 16 | 1949.14 | 0.09 | 0.17 | 0.09 |
for t in model_eqs:
print(t)
Poly 1:
y = 1.89 - 2.12*x0
Poly 2:
y = 2.12 - 2.10*x0 - 0.61*x0^2
Poly 4:
y = 2.12 + 1.02*x0 - 0.57*x0^2 - 4.35*x0^3 + 0.04*x0^4
Poly 8:
y = 2.12 + 0.38*x0 - 1.26*x0^2 - 1.71*x0^3 + 4.88*x0^4 - 1.95*x0^5 - 9.75*x0^6 - 0.27*x0^7 + 5.66*x0^8
Poly 16:
y = 2.35 + 2.63*x0 - 26.64*x0^2 - 91.67*x0^3 + 406.72*x0^4 + 845.30*x0^5 - 2567.79*x0^6 - 3314.14*x0^7 + 8352.32*x0^8 + 6567.95*x0^9 - 15246.20*x0^10 - 7029.38*x0^11 + 15772.43*x0^12 + 3911.09*x0^13 - 8640.13*x0^14 - 895.20*x0^15 + 1949.14*x0^16
Lasso (alpha:0.02):
y = 2.08 - 0.49*x0^2 - 0.73*x0^3 - 2.67*x0^5 + 0.09*x0^16
Ridge (alpha:3.16):
y = 2.08 - 0.21*x0 - 0.39*x0^2 - 0.91*x0^3 - 0.27*x0^4 - 0.89*x0^5 - 0.15*x0^6 - 0.65*x0^7 - 0.01*x0^8 - 0.40*x0^9 + 0.08*x0^10 - 0.23*x0^11 + 0.14*x0^12 - 0.12*x0^13 + 0.17*x0^14 - 0.06*x0^15 + 0.17*x0^16
Elastic Net (alpha:0.02, l1:0.90:
y = 2.08 - 0.50*x0^2 - 0.78*x0^3 - 2.61*x0^5 + 0.09*x0^16
True model:
y = 2.00 + 0.90*x0 - 4.20*x0^3 - 0.50*x0^4
Which model is best?
## Example: Auto HP vs MPG
Horsepower and fuel efficiency are known to have a non-linear relationship. Let's try resolving this relationship with polynomial features.
Cell In[14], line 3
Horsepower and fuel efficiency are known to have a non-linear relationship. Let's try resolving this relationship with polynomial features.
^
SyntaxError: unterminated string literal (detected at line 3)
data_df = pd.read_csv('https://raw.githubusercontent.com/shreyamdg/automobile-data-set-analysis/refs/heads/master/cars.csv')
data_df.head()
data_df.columns
Index(['Unnamed: 0', 'symboling', 'normalized-losses', 'make', 'fuel-type',
'aspiration', 'num-of-doors', 'body-style', 'drive-wheels',
'engine-location', 'wheel-base', 'length', 'width', 'height',
'curb-weight', 'engine-type', 'num-of-cylinders', 'engine-size',
'fuel-system', 'bore', 'stroke', 'compression-ratio', 'horsepower',
'peak-rpm', 'city-mpg', 'highway-mpg', 'price'],
dtype='object')
cars_df = data_df.query('`fuel-type`=="gas"')
# Focus on horsepower vs MPG
cars_df = cars_df[['horsepower', 'city-mpg']]
cars_df['horsepower'].unique()
array(['111', '154', '102', '115', '110', '140', '160', '101', '121',
'182', '48', '70', '68', '88', '145', '58', '76', '60', '86',
'100', '78', '90', '176', '262', '135', '84', '120', '155', '184',
'175', '116', '69', '97', '152', '200', '95', '142', '143', '207',
'288', '?', '73', '82', '94', '62', '112', '92', '161', '156',
'85', '114', '162', '134'], dtype=object)
cars_df['horsepower'] = pd.to_numeric(cars_df['horsepower'], errors = 'coerce')
cars_df.dropna(inplace=True)
cars_df['horsepower'].unique()
array([111., 154., 102., 115., 110., 140., 160., 101., 121., 182., 48.,
70., 68., 88., 145., 58., 76., 60., 86., 100., 78., 90.,
176., 262., 135., 84., 120., 155., 184., 175., 116., 69., 97.,
152., 200., 95., 142., 143., 207., 288., 73., 82., 94., 62.,
112., 92., 161., 156., 85., 114., 162., 134.])
X = cars_df[['horsepower']]
y = cars_df['city-mpg']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
# Fit linear model
linreg = LinearRegression()
linreg.fit(X, y)
y_pred_lin = linreg.predict(X)
# Fit polynomial model (degree 2)
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
lin_poly = LinearRegression()
lin_poly.fit(X_poly, y)
y_pred_poly = lin_poly.predict(X_poly)
# Compare
print(f"Linear R²: {r2_score(y, y_pred_lin):.4f}")
print(f"Polynomial R²: {r2_score(y, y_pred_poly):.4f}")
# Visualize
X_sorted = np.sort(X, axis=0)
X_sorted_poly = poly.transform(X_sorted)
fig, ax = plt.subplots(1,2, figsize=(12, 5))
ax[0].plot(X, y, '.', alpha=0.5)
ax[0].plot(X_sorted, linreg.predict(X_sorted), 'b-', linewidth=2, label='Linear')
ax[0].set_xlabel('Horsepower')
ax[0].set_ylabel('MPG')
ax[0].set_title('Linear Model (just hp)')
ax[0].legend()
plt.plot(X, y, '.', alpha=0.5)
plt.plot(X_sorted, poly_model.predict(X_sorted_poly), 'r-', linewidth=2, label='Polynomial (degree 2)')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.title('Polynomial Model (hp and hp^2)')
plt.legend()
plt.tight_layout()
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[23], line 2
1 # Compare
----> 2 print(f"Linear R²: {r2_score(y, y_pred_lin):.4f}")
3 print(f"Polynomial R²: {r2_score(y, y_pred_poly):.4f}")
5 # Visualize
NameError: name 'r2_score' is not defined