
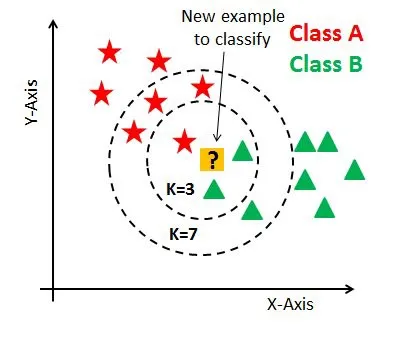
9. K-Nearest Neighbors (KNN) (a lazy learner)#
A K-Nearest Neighbors classifier doesn’t really learn a model at all. Instead, to determine the label for an unknown sample, it finds the K data points from the training set closest to the unlabeled sample (the K nearest neighbors) and assigns the majority label among the nearest neighbors.
9.1. Eager vs Lazy models#
Eager learners spend more time and resources training a simple model that generalizes and prediction is quick and not computationally intensive (simple, quick, and computationally intensive are all relative).
Lazy learners store data and do most of the computation at the time of prediction. Lazy learners are slower to predict, but they are also adaptable to new data because the training overhead is low.
KNN is a very lazy learner!
9.2. Hyper parameters of KNN#
sklearn.neighbors.KNeighborsClassifier
n_neighbors- number of neighbors (why not k?! come on sklearn devs!). Rule of thumb, start with square root of number of samples.If k is too small, the model will be too specific and won’t generalize well to new data. The classifier will fit the training data well, but fail to generalize to the test set. This is called overfitting.
If k is too large, the model will fail to predict correct labels in the training set. This is called underfitting.
metric- the metric is how distance is calculated between samples. Two common metrics to use:Euclidean distance - “euclidean” - \(d(p,q) = \sqrt{(p_1-q_1)^2 + (p_2-q_2)^2 + \cdots + (p_m-q_m)^2 }\)
Manhattan distance - “manhattan” - \(d(p,q) = |p_1-q_1| + |p_2-q_2| + \cdots + |p_m-q_m|^2\)
from sklearn.neighbors import KNeighborsClassifier
fig, ax = plt.subplots(1,1, figsize = (5,5))
knn = KNeighborsClassifier(n_neighbors = 3)
knn.fit(X_train, y_train)
y_pred = knn.predict(X_test)
knn_boundaries = DecisionBoundaryDisplay.from_estimator(knn, X=X_train,
xlabel = 'bill_length_mm',
ylabel = 'bill_depth_mm',
response_method = 'predict',
cmap = cmap, alpha = 0.5,
ax=ax)
ax.scatter(X_train['bill_length_mm'], X_train['bill_depth_mm'],
c = z_train, cmap=cmap,
marker = '.', s = 50, label = label_names)
ax.scatter(X_test['bill_length_mm'], X_test['bill_depth_mm'],
c = z_test, cmap = cmap,
marker = '+', s=50)
plt.show()
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 3
1 from sklearn.neighbors import KNeighborsClassifier
----> 3 fig, ax = plt.subplots(1,1, figsize = (5,5))
5 knn = KNeighborsClassifier(n_neighbors = 3)
7 knn.fit(X_train, y_train)
NameError: name 'plt' is not defined
9.3. Example: MNIST#
The MNIST data set comprises small images (8x8 pixels) of hand-written digits. We’ll apply KNN as a classifier to determine which digit a hand-written image represents.
from sklearn.datasets import load_digits
digits = load_digits()
fig, axes = plt.subplots(nrows=1, ncols=10, figsize=(15, 3), sharey=True)
for ax, image, label in zip(axes, digits['images'], digits['target']):
ax.set_xticks(range(0,8))
ax.set_yticks(range(0,8))
ax.imshow(image, cmap=plt.cm.gist_gray, interpolation="nearest")
ax.set_title(f'Example: {label}')

Each image is composed of 64 pixels with values from 0-15. Each image is a data point and each pixel value will be a feature of our data. To work with these images, we’ll want to unfurl them from an 8x8 square matrix to an array of 64 elements.
The custom functions unfurl_imageset and refurl_imageset will let us go back and forth between the image and vector formats.
def unfurl_imageset(image_set):
if len(image_set.shape)==2:
num_images = 1
else:
num_images = len(image_set)
return image_set.reshape((num_images, -1))
def refurl_imageset(vector_set, image_size):
if len(vector_set.shape)==1:
return vector_set.reshape((image_size[0], image_size[1]))
else:
num_vectors = len(vector_set)
return vector_set.reshape((num_vectors, image_size[0], image_size[1]))
vector_0 = unfurl_imageset(digits['images'][0])
fig, ax0 = plt.subplots(1,1, figsize = (6, 6))
image_cmap = plt.cm.gist_gray
sns.heatmap(digits['images'][0], annot = True,
cmap=image_cmap, cbar = False,
ax = ax0)
ax0.set_aspect('equal')
ax0.set_title('Original Image')
fig, ax1 = plt.subplots(1,1, figsize = (15, 5))
sns.heatmap(vector_0, annot = True,
cmap=image_cmap, cbar = False,
ax = ax1)
ax1.set_aspect('equal')
ax1.set_title('Image Unfurled')
plt.show()


X = unfurl_imageset(digits['images'])
y = digits['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)
pca = PCA(n_components = 64)
P_train = pca.fit_transform(X_train)
P_test = pca.transform(X_test)
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_pca.py:606: RuntimeWarning: divide by zero encountered in matmul
C = X.T @ X
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_pca.py:606: RuntimeWarning: overflow encountered in matmul
C = X.T @ X
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_pca.py:606: RuntimeWarning: invalid value encountered in matmul
C = X.T @ X
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: divide by zero encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: overflow encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: invalid value encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: divide by zero encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: overflow encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: invalid value encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: divide by zero encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: overflow encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:148: RuntimeWarning: invalid value encountered in matmul
X_transformed = X @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: divide by zero encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: overflow encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
/Users/eatai/.pyenv/versions/datascience/lib/python3.13/site-packages/sklearn/decomposition/_base.py:155: RuntimeWarning: invalid value encountered in matmul
X_transformed -= xp.reshape(self.mean_, (1, -1)) @ self.components_.T
pca.__dict__
{'n_components': 64,
'copy': True,
'whiten': False,
'svd_solver': 'auto',
'tol': 0.0,
'iterated_power': 'auto',
'n_oversamples': 10,
'power_iteration_normalizer': 'auto',
'random_state': None,
'n_features_in_': 64,
'_fit_svd_solver': 'covariance_eigh',
'mean_': array([0.00000000e+00, 3.04105776e-01, 5.24077940e+00, 1.17814892e+01,
1.18956159e+01, 5.79679889e+00, 1.32567850e+00, 1.28740431e-01,
4.87125957e-03, 2.02226862e+00, 1.04405010e+01, 1.19123173e+01,
1.02727905e+01, 8.16005567e+00, 1.82811413e+00, 1.06471816e-01,
2.08768267e-03, 2.60473208e+00, 9.89004871e+00, 7.01809325e+00,
7.12386917e+00, 7.84551148e+00, 1.78705637e+00, 4.31454419e-02,
1.39178845e-03, 2.48503827e+00, 9.15309673e+00, 8.91231733e+00,
9.95755045e+00, 7.56367432e+00, 2.25956855e+00, 2.78357690e-03,
0.00000000e+00, 2.27696590e+00, 7.71259569e+00, 9.03827418e+00,
1.03263744e+01, 8.78705637e+00, 2.91231733e+00, 0.00000000e+00,
9.04662491e-03, 1.53583855e+00, 6.81002088e+00, 7.08977035e+00,
7.70146138e+00, 8.29018789e+00, 3.45720251e+00, 3.06193459e-02,
6.95894224e-03, 6.94502436e-01, 7.44119694e+00, 9.45998608e+00,
9.45163535e+00, 8.78775226e+00, 3.70215727e+00, 2.08768267e-01,
0.00000000e+00, 2.79749478e-01, 5.58037578e+00, 1.20848991e+01,
1.18455115e+01, 6.77592206e+00, 2.08907446e+00, 3.63256785e-01]),
'noise_variance_': 0.0,
'n_samples_': 1437,
'n_components_': 64,
'components_': array([[ 0.00000000e+00, -1.71123566e-02, -2.22664924e-01, ...,
-9.17315638e-02, -3.83328058e-02, -1.14166536e-02],
[ 0.00000000e+00, 9.70087510e-03, 5.62438806e-02, ...,
-1.68672288e-01, -1.36591242e-02, 7.54772349e-03],
[ 0.00000000e+00, -1.93103438e-02, -1.38811555e-01, ...,
-2.24200077e-01, -1.69502116e-01, -3.38289078e-02],
...,
[ 1.00000000e+00, 0.00000000e+00, 0.00000000e+00, ...,
0.00000000e+00, 0.00000000e+00, 0.00000000e+00],
[-0.00000000e+00, -0.00000000e+00, -1.00526902e-16, ...,
-2.09063383e-17, -1.27774820e-16, 8.11435712e-17],
[-0.00000000e+00, -0.00000000e+00, 9.16429056e-16, ...,
-2.20971426e-16, 3.06168694e-15, -2.50478522e-15]],
shape=(64, 64)),
'explained_variance_': array([1.81151081e+02, 1.59646524e+02, 1.42659353e+02, 1.00447410e+02,
7.04930593e+01, 6.04437852e+01, 5.23395073e+01, 4.41004820e+01,
4.02180746e+01, 3.67353687e+01, 2.89495106e+01, 2.66032021e+01,
2.10199729e+01, 2.08509243e+01, 1.76283045e+01, 1.69381896e+01,
1.57399179e+01, 1.44977576e+01, 1.21842282e+01, 1.10307116e+01,
1.04605544e+01, 9.64528097e+00, 9.09248738e+00, 8.66023081e+00,
8.56965051e+00, 7.11607232e+00, 6.96543924e+00, 6.15067672e+00,
5.76952321e+00, 5.19016804e+00, 4.52286947e+00, 4.22978372e+00,
4.01443984e+00, 3.86945412e+00, 3.82802047e+00, 3.52746794e+00,
3.11665649e+00, 2.75656954e+00, 2.55327396e+00, 2.50310777e+00,
2.26750600e+00, 1.89979375e+00, 1.77638058e+00, 1.63668409e+00,
1.42956526e+00, 1.30200912e+00, 1.10861486e+00, 9.51823710e-01,
5.98263652e-01, 4.68696365e-01, 2.41561373e-01, 9.54151485e-02,
7.23232843e-02, 5.20775540e-02, 4.36175104e-02, 1.52964823e-02,
6.99674940e-03, 3.89862191e-03, 1.19923644e-03, 6.74859504e-04,
3.17613215e-16, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]),
'explained_variance_ratio_': array([1.50935149e-01, 1.33017544e-01, 1.18863826e-01, 8.36928197e-02,
5.87348434e-02, 5.03617845e-02, 4.36092972e-02, 3.67445382e-02,
3.35097148e-02, 3.06079230e-02, 2.41207431e-02, 2.21657980e-02,
1.75138493e-02, 1.73729980e-02, 1.46879099e-02, 1.41129059e-02,
1.31145055e-02, 1.20795370e-02, 1.01519035e-02, 9.19079302e-03,
8.71573781e-03, 8.03645172e-03, 7.57586390e-03, 7.21570756e-03,
7.14023602e-03, 5.92911413e-03, 5.80360659e-03, 5.12474615e-03,
4.80716890e-03, 4.32444996e-03, 3.76845654e-03, 3.52425738e-03,
3.34483278e-03, 3.22403062e-03, 3.18950809e-03, 2.93908761e-03,
2.59679936e-03, 2.29677477e-03, 2.12738882e-03, 2.08559033e-03,
1.88928685e-03, 1.58290887e-03, 1.48008097e-03, 1.36368580e-03,
1.19111431e-03, 1.08483449e-03, 9.23698319e-04, 7.93059872e-04,
4.98473500e-04, 3.90517987e-04, 2.01269026e-04, 7.94999376e-05,
6.02597877e-05, 4.33910375e-05, 3.63421260e-05, 1.27450348e-05,
5.82969423e-06, 3.24833324e-06, 9.99204252e-07, 5.62293192e-07,
2.64635450e-19, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00]),
'singular_values_': array([5.10032306e+02, 4.78803101e+02, 4.52613335e+02, 3.79792681e+02,
3.18163532e+02, 2.94613774e+02, 2.74152389e+02, 2.51651132e+02,
2.40318861e+02, 2.29678013e+02, 2.03890896e+02, 1.95453826e+02,
1.73737391e+02, 1.73037358e+02, 1.59104510e+02, 1.55959098e+02,
1.50341352e+02, 1.44287144e+02, 1.32274532e+02, 1.25857466e+02,
1.22561642e+02, 1.17688672e+02, 1.14266407e+02, 1.11517225e+02,
1.10932494e+02, 1.01087486e+02, 1.00011853e+02, 9.39806989e+01,
9.10221694e+01, 8.63312302e+01, 8.05905737e+01, 7.79356749e+01,
7.59258560e+01, 7.45421768e+01, 7.41420083e+01, 7.11719324e+01,
6.68993178e+01, 6.29160858e+01, 6.05516425e+01, 5.99538385e+01,
5.70625851e+01, 5.22312534e+01, 5.05062621e+01, 4.84796695e+01,
4.53084509e+01, 4.32398554e+01, 3.98995105e+01, 3.69705132e+01,
2.93105204e+01, 2.59431683e+01, 1.86247720e+01, 1.17053899e+01,
1.01909880e+01, 8.64773771e+00, 7.91421158e+00, 4.68676313e+00,
3.16975269e+00, 2.36609828e+00, 1.31228942e+00, 9.84427879e-01,
6.75346264e-07, 0.00000000e+00, 0.00000000e+00, 0.00000000e+00])}
X.shape
P_train.shape
(1437, 64)
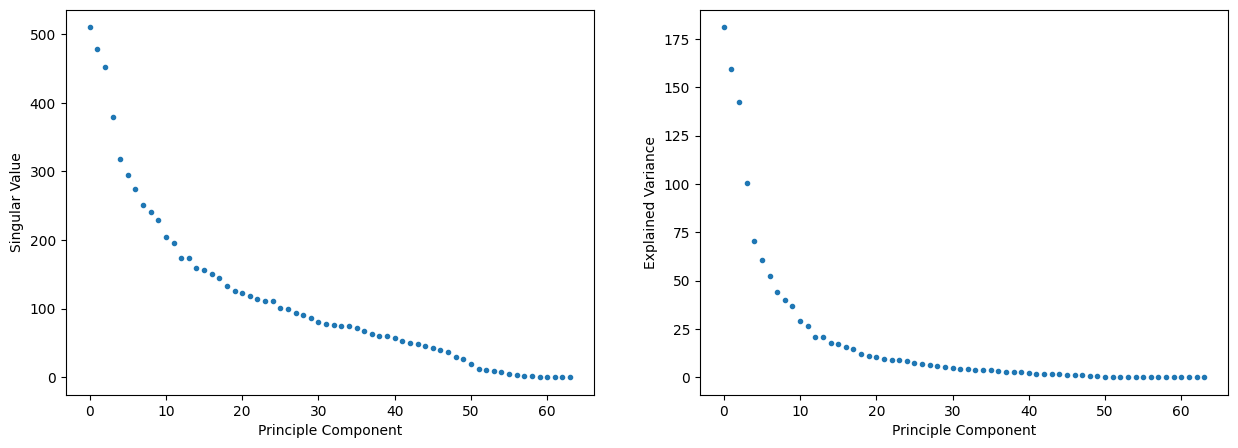
fig, ax = plt.subplots(1,2, figsize = (15, 5))
ax[0].plot(pca.singular_values_, marker='.', linestyle='none')
ax[0].set_xlabel('Principle Component')
ax[0].set_ylabel('Singular Value')
ax[1].plot(pca.explained_variance_, marker='.', linestyle='none')
ax[1].set_xlabel('Principle Component')
ax[1].set_ylabel('Explained Variance')
Text(0, 0.5, 'Explained Variance')
fig, ax = plt.subplots(1,10, figsize = (15,4), sharey=True)
for n in range(10):
image = refurl_imageset(pca.components_[n], [8,8])
ax[n].imshow(image, cmap = image_cmap)
ax[n].set_title(f'PC {n}')

from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay, classification_report
P_train = P_train[:,0:5]
P_test = P_test[:, 0:5]
knn_clf = KNeighborsClassifier(n_neighbors = 3)
knn_clf.fit(P_train, y_train)
y_train_pred = knn_clf.predict(P_train)
y_pred = knn_clf.predict(P_test)
cfm = confusion_matrix(y_true = y_test, y_pred=y_pred)
ConfusionMatrixDisplay(cfm).plot()
print('TRAINING REPORT:')
print(classification_report(y_train, y_train_pred))
print('TESTING REPORT:')
print(classification_report(y_test, y_pred))
TRAINING REPORT:
precision recall f1-score support
0 1.00 0.99 1.00 138
1 0.97 0.98 0.98 145
2 0.95 0.94 0.95 137
3 0.95 0.91 0.93 152
4 0.97 0.99 0.98 145
5 0.97 0.98 0.98 149
6 0.99 0.99 0.99 142
7 0.93 0.96 0.94 142
8 0.91 0.89 0.90 141
9 0.91 0.92 0.92 146
accuracy 0.95 1437
macro avg 0.95 0.95 0.95 1437
weighted avg 0.95 0.95 0.95 1437
TESTING REPORT:
precision recall f1-score support
0 0.98 1.00 0.99 40
1 0.90 0.97 0.94 37
2 0.90 0.90 0.90 40
3 0.93 0.84 0.88 31
4 0.97 0.92 0.94 36
5 1.00 0.91 0.95 33
6 1.00 0.97 0.99 39
7 0.92 0.92 0.92 37
8 0.74 0.76 0.75 33
9 0.82 0.91 0.86 34
accuracy 0.91 360
macro avg 0.91 0.91 0.91 360
weighted avg 0.92 0.91 0.91 360
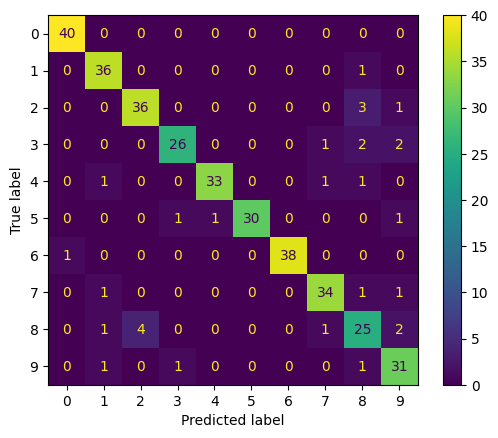
What could we try to improve the prediction?